-
2024-01-13~2024-01-14스파르타/TIL(Today I Learned) 2024. 1. 15. 23:15더보기
SQL 코드카타
1068. Product Sales Analysis I(SQL) (inner join)
https://leetcode.com/problems/product-sales-analysis-i/description/
두 테이블을 가져와서 각 Sale_id에 대해 product_name, year, price를 출력하는 문제이다
SELECT p.product_name, s.year, s.price FROM Sales s INNER JOIN Product p ON s.product_id = p.product_id;1581. Customer Who Visited but Did Not Make Any Transactions(SQL)(left join)
https://leetcode.com/problems/customer-who-visited-but-did-not-make-any-transactions/description/
방문한 고객들 중 거래를 하지 않은 고객들에 대해 고객_id와 몇 번 방문했는지를 표시하는 문제이다.
SELECT v.customer_id, count(v.visit_id) count_no_trans FROM Visits v LEFT JOIN Transactions t on v.visit_id =t.visit_id WHERE t.transaction_id IS NULL GROUP BY v.customer_id;나는 join을 통해 풀어주었는데 나보다 빠른 런타임을 가진 사람 중에 서브쿼리로 했던 사람이 있던 것 같았는데 왜 더 빨랐는지 모르겠다.
나보다 더 짧은 런타임을 가졌던 쿼리들은 아래와 같다
# Write your MySQL query statement below select customer_id,count(*) as count_no_trans from Visits where visit_id not in (select visit_id from transactions) group by customer_id # Write your MySQL query statement below select v.customer_id,count(v.customer_id) count_no_trans from Visits v left join (select transaction_id ,visit_id from Transactions ) t on v.visit_id = t.visit_id where t.transaction_id is null group by v.customer_id # Write your MySQL query statement below /* Write your PL/SQL query statement below */ SELECT customer_id, count(*) AS count_no_trans FROM Visits WHERE visit_id NOT IN (SELECT visit_id FROM Transactions ) GROUP BY customer_id # Write your MySQL query statement below SELECT customer_id, COUNT(*) AS count_no_trans FROM Visits v WHERE NOT EXISTS (SELECT 1 FROM Transactions WHERE v.visit_id = visit_id) GROUP BY customer_id197. Rising Temperature(SQL) (lag, where 서브쿼리 조건, 날짜관련 조건, 이전날짜에 대한 값, datediff, inner join, 셀프조인self join, date_sub interval 1 day)
https://leetcode.com/problems/rising-temperature/description/
어제보다 온도가 높은 날짜를 모두 출력하는 문제이다.
# Write your MySQL query statement below SELECT w.id FROM Weather w WHERE w.temperature>(SELECT LAG(w_s.temperature) OVER() FROM Weather w_s WHERE w.id=w_s.id)이 것은 제일 처음 런타임 에러가 뜬 쿼리로
이번에는 어제의 온도와 어떻게 비교해야할지 잘 떠오르지 않아 꽤 오래걸렸다. 뭔가 안될 듯하면서도 될 것 같아서 시도해보았는데 안됬었다(1개보다 더 많은 값을 줘서 그렇다고 한다) 그래서 WHERE w.id=w_s.id를 붙여줬더니 실행은 됬지만, 아무 값도 리턴되지 않았다 (그 이유는 아직 잘 모르겠다)
WITH pre_date AS( SELECT id, LAG(w_s.temperature) OVER(ORDER BY recordDate) pre_temp FROM Weather w_s ) SELECT w.id FROM Weather w WHERE w.temperature>(SELECT pre_temp FROM pre_date p WHERE w.id = p.id)그래서 WITH구문을 사용하여 임시테이블을 만들고 LAG를 통해 바로 이전의 온도값을 가져왔는데 처음에는 문제에서 주는 데이터가 다 정렬되어있겠지 생각하여 order by recordDate를 제외하고 하였었는데 그렇지 않은 문제가 있어서 추가해주니 그부분은 해결된 것 같았지만 아래같은 케이스를 생각 하지 못하였어서 통과하지 못하였다(날짜 간격이 1일이 아니라 그 이상 벌어져있는 경우)
| id | recordDate | temperature | | -- | ---------- | ----------- | | 1 | 2000-12-14 | 3 | | 2 | 2000-12-16 | 5 |SELECT w.id FROM Weather w WHERE w.temperature>(SELECT w_s.temperature FROM weather w_s WHERE w.recordDate-1 = w_s.recordDate) ORDER BY w.recordDate그래서 그다음에는 서브쿼리를 사용하여 recordDate에 대해 -1되는 값을 가지는 서브쿼리로 조건을 잡아주었는데 왜인지는 모르겠으나 매우 값들이 뒤죽박죽하고 전에 할때 날짜에 대해서 -1로 차를 구해버리면 이상한 값이 나왔던 것 같아서 datediff를 사용해주었다
실패한 테스트 케이스는 노션에는 기록해 두었으나 블로그에 적기에는 너무 길어서 생략하겠다.
SELECT w.id FROM Weather w WHERE w.temperature>(SELECT w_s.temperature FROM weather w_s WHERE DATEDIFF(w.recordDate,w_s.recordDate) = 1) ORDER BY w.recordDate이렇게 하니 모든 문제가 해결되긴 했는데 어지간히 성능이 안 좋았던 것 같다(제출한 사람 중 거의 꼴지의 런타임이였다) 내가 생각해도 그럴 것 같기는 했는데 다른 방법으로 어떻게 해야하는지 떠오르지 않아서 별다른 수가 없었다. 그래서 엄청 빠른 사람은 어떻게 했나 보았는데 모르는 부분이 굉장히 많아서 이해 되지 않았다
# Write your MySQL query statement below SELECT W2.id FROM Weather AS W1 INNER JOIN Weather AS W2 ON DATE_SUB(W2.recordDate, INTERVAL 1 DAY)=W1.recordDate WHERE W1.temperature<W2.temperature;우선 같은 테이블을 서로 조인해줬으므로 셀프조인을 사용하였는 것까지는 이해하겠는데 date_sub을 처음보고 interval 1 day같은 표현?은 처음 본다 검색해본 결과 특정 시간, 날짜를 기준으로 더하거나 뺄 때 사용하는 함수라고 한다. 이 사실을 참고하여 한번 쿼리를 해석해보면
우선 weather테이블을 w1과 w2로 각각 다르게 별명을 붙여서 inner join해주는데 w2의 recordDate에 1을 뺸 값과 w1의 recordDate 값이 같도록 inner join해준다 이렇게 하면 w2의 날짜보다 w1의 날짜가 하루전인 것과 동일하게 매칭?시켜줬으니 w1이 전날, w2가 확인날짜가 되므로 w2의 온도가 w1의 온도보다 높은 날의 id를 출력해주는 쿼리이다.
1661. Average Time of Process per Machine(SQL) (round, case when & max null제외, with, join의 공통컬럼 조건(on) 여러개) (좀더 공부해볼만한 내용있음!)
https://leetcode.com/problems/average-time-of-process-per-machine/description/
기계별로 각 같은 수의 프로세스를 처리하게 되는데 기계마다 각 프로세스를 처리하는데 시간이 다르다. 각 기계별 프로세스 평균처리 시간을 구하는 문제이다.
SELECT sub.machine_id, round(AVG(sub.difference),3) processing_time FROM (SELECT a_e.machine_id, a_e.process_id , round(MAX(CASE WHEN activity_type = 'end' THEN timestamp END) - MAX(CASE WHEN activity_type = 'start' THEN timestamp END),3) AS difference FROM Activity a_e GROUP BY a_e.machine_id, a_e.process_id) sub GROUP BY sub.machine_id이것이 처음에 제출한 쿼리로 우선 서브쿼리로 Activity 테이블을 가져와서 machine_id와 process_id에 대해 그룹을 짓고, machine_id, process_id 그리고 type이 end인 timestamp-type이 start인 timestamp를 빼준뒤 소수점 셋째자리까지 반올림하여 표시하는 쿼리인데 그 뒤 메인 쿼리에서 machine_id에 대해 그룹을 지은 뒤, machine_id와 그것에 대해 서브쿼리에서 구한 차이를 평균낸 쿼리이다. 살짝 헷깔려가면서 작성했는데 서브쿼리 부분에서 max를 써야하나 말아야하나 고민했는데 전에 엑셀보다 쉬운 SQL 강의에서 했던 piviot부분 했던 것 처럼 같은 원래로 case when에 대하여 표시는 되지 않지만 여러 데이터들에 대해 확인하고 다루게 되는데 한 프로세스에 대해 데이터가 end와 start의 두개의 데이터가 존재하는데 end가 조건 일 때는 end인 경우 값이 나오지만 start인 경우 내가 따로 값을 리턴을 어떻게 해줘라 정하지 않았기에 null로 나오게 된다 따라서 만약 null값이 있으면 상황에 따라(먼저 null이 나오는 경우?아마 null이 포함되면 그냥 무조건 null로 나올 듯 한데 이부분은 나중에 확인을 해봐야 할듯하다) null값이 나와버릴 수 있기 때문에 둘중 큰 값을 리턴해주게 하여 내가 의도한 값이 리턴되게 해주기 위해 사용하였다.
WITH end_val AS( SELECT a_e.machine_id, a_e.process_id , a_e.timestamp end_time FROM Activity a_e WHERE a_e.activity_type='end' GROUP BY a_e.machine_id, a_e.process_id ), start_val AS( SELECT a_s.machine_id, a_s.process_id , a_s.timestamp start_time FROM Activity a_s WHERE a_s.activity_type='start' GROUP BY a_s.machine_id, a_s.process_id ) SELECT e.machine_id, ROUND(SUM(e.end_time - s.start_time)/count(e.process_id),3) processing_time FROM end_val e INNER JOIN start_val s ON e.machine_id = s.machine_id and e.process_id = s.process_id GROUP BY e.machine_id;처음에 아이디어 떠올라서 작성하다가 도중에 다른 아이디어 떠올라서 두번째로 제출한 쿼리인데, 결과로만 보면 첫번째 제출한 쿼리가 전체 테스트 404ms, 두번째 쿼리가 369ms로 두번째 쿼리가 성능이 더 좋은 듯하다. 아마 서브쿼리를 사용하지 않아서 그런듯하다.(자세한 이유는 더 알아봐야 알 수 있을듯하다.)
쿼리에 대해서 설명해보면 우선 with구문을 통해 end_val, start_val 두개의 테이블을 선언하는데 각각 end에 대한 값과 start에 대한 값의 테이블이며, 각 조건이 해당하는 machine_id, process_id, timestamp를 출력하는 쿼리로 되어있다. 그런 뒤 두 테이블을 machine_id과 process_id를 공통컬럼으로 하여 join하여 가져오는데 machine_id에 대해 그룹지었다. 그 뒤 machine_id와 (end_time과 start_time의 차의 총합) / 프로세스 갯수 하여 평균을 구한 뒤 round를 통해 소수 셋째자리 까지 반올림하여 나타내어주었다.
여기서 주의해야할 점은 join시 조건을 machine_id에 대해서만 해준다면 process에 대해서도 여러개라 process에 대한 timestamp값이 여러 개 대응되어 이상하게 값이 나올 수 있다(말을 좀 이상하게 설명한 듯 하여 예시를 적어두겠다)
machine_id process_id activity_type timestamp0 0 start 0.712 0 0 end 1.52 0 1 start 3.14 0 1 end 4.12 1 0 start 0.55 1 0 end 1.55 1 1 start 0.43 1 1 end 1.42 2 0 start 4.1 2 0 end 4.512 2 1 start 2.5 2 1 end 5 딱 on부분만 건드였을 경우
machine_id와 process_id 둘다에 대해 해준 경우
WITH end_val AS( SELECT a_e.machine_id, a_e.process_id , a_e.timestamp end_time FROM Activity a_e WHERE a_e.activity_type='end' GROUP BY a_e.machine_id, a_e.process_id ), start_val AS( SELECT a_s.machine_id, a_s.process_id , a_s.timestamp start_time FROM Activity a_s WHERE a_s.activity_type='start' GROUP BY a_s.machine_id, a_s.process_id ) SELECT e.machine_id, e.end_time , s.start_time FROM end_val e INNER JOIN start_val s ON e.machine_id = s.machine_id and e.process_id = s.process_id GROUP BY e.machine_id;
machine_id에 대해서마나 해준 경우
WITH end_val AS( SELECT a_e.machine_id, a_e.process_id , a_e.timestamp end_time FROM Activity a_e WHERE a_e.activity_type='end' GROUP BY a_e.machine_id, a_e.process_id ), start_val AS( SELECT a_s.machine_id, a_s.process_id , a_s.timestamp start_time FROM Activity a_s WHERE a_s.activity_type='start' GROUP BY a_s.machine_id, a_s.process_id ) SELECT e.machine_id, e.end_time , s.start_time FROM end_val e INNER JOIN start_val s ON e.machine_id = s.machine_id GROUP BY e.machine_id;
설명하고 싶은 의도대로 보인다면
machine_id와 process_id 둘다에 대해 해준 경우
WITH end_val AS( SELECT a_e.machine_id, a_e.process_id , a_e.timestamp end_time FROM Activity a_e WHERE a_e.activity_type='end' GROUP BY a_e.machine_id, a_e.process_id ), start_val AS( SELECT a_s.machine_id, a_s.process_id , a_s.timestamp start_time FROM Activity a_s WHERE a_s.activity_type='start' GROUP BY a_s.machine_id, a_s.process_id ) SELECT e.machine_id, e.process_id, e.end_time , s.start_time FROM end_val e INNER JOIN start_val s ON e.machine_id = s.machine_id and e.process_id = s.process_id GROUP BY e.machine_id,e.process_id;
machine_id에 대해서마나 해준 경우
WITH end_val AS( SELECT a_e.machine_id, a_e.process_id , a_e.timestamp end_time FROM Activity a_e WHERE a_e.activity_type='end' GROUP BY a_e.machine_id, a_e.process_id ), start_val AS( SELECT a_s.machine_id, a_s.process_id , a_s.timestamp start_time FROM Activity a_s WHERE a_s.activity_type='start' GROUP BY a_s.machine_id, a_s.process_id ) SELECT e.machine_id, e.process_id, e.end_time , s.start_time FROM end_val e INNER JOIN start_val s ON e.machine_id = s.machine_id GROUP BY e.machine_id,e.process_id;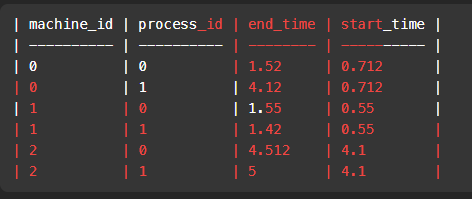
577. Employee Bonus(SQL) (왜 runtime이리 많이 차이?)
https://leetcode.com/problems/employee-bonus/
보너스가 1000보다 작은 사원의 이름과 보너스를 출력하는 문제이다.
SELECT e.name, b.bonus FROM Employee e LEFT JOIN Bonus b ON e.empId = b.empId WHERE b.bonus < 1000 OR b.bonus IS NULL;내가 제출한 쿼리로 Employee테이블에 Bonus테이블을 empId를 공통컬럼으로 하여 Left join해준뒤, bonus가 1000미만이거나 없는(join으로 인해 null을 가지게 되는) 데이터에 대하여 이름과 데이터를 출력하는 쿼리이다
select e.name, b.bonus from Employee e left join Bonus b on e.empId = b.empId where b.bonus < 1000 or b.bonus is null ;1419ms걸린분의 쿼리인데 내 쿼리와 차이가 뭔지 모르겠다…(내 쿼리는 5284ms이다)
'스파르타 > TIL(Today I Learned)' 카테고리의 다른 글
2024-01-16 (0) 2024.01.16 2024-01-15 (2) 2024.01.15 2024-01-1 (2) 2024.01.12 2024-01-11 (2) 2024.01.11 2024-01-10 (0) 2024.01.10