-
2024-01-1스파르타/TIL(Today I Learned) 2024. 1. 12. 23:12더보기
SQL 코드카타
1683. Invalid Tweets(SQL) (length)
https://leetcode.com/problems/invalid-tweets/submissions/1143909780/
SELECT t.tweet_id FROM Tweets t WHERE LENGTH(content)>15;LENGTH,CHAR_LENGTH, CAHRACTER_LENGTH가 있음
사용법은 보이는 대로 그냥 LENGTH (문자열)하면됨
1378. Replace Employee ID With The Unique Identifier(SQL) (LEFT JOIN)
https://leetcode.com/problems/replace-employee-id-with-the-unique-identifier/description/
Employees테이블과 EmployeeUNI테이블을 주고 각 유저의 고유id와 이름을 표시하는 문제이다(고유id가 없으면 null로)
SELECT CASE WHEN eu.unique_id is NULL THEN NULL ELSE eu.unique_id END unique_id, e.name FROM Employees e LEFT JOIN EmployeeUNI eu on e.id = eu.id처음에는 EmployeeUNI테이블에 모든 id가 있다고 생각하고 작성하여 저런 식으로 case when을 사용하였는데 제출하고 나서 확인하다가 깨달았는데 어차피 left join으로 (제일 처음 시도는 둘다 모든 id가 있다고 생각하여 inner join을 했었다 그래서 둘이 공통된 내용만 나오기에 틀린 결과가 나왔다) 해주니 EmployeeUNI에 없는 아이디에 대해서는 어차피 null값으로 표시되니 따로 case when을 쓸 필요 없이 아래와 같이 간단히 left join만 해주면 되는 문제였다.(그리고 사실 런타임도 2643ms에서 2036ms로 줄었다 사실 여전히 확실히 어떻게 하면 줄일 수 있는지는 명확히 감이 오지 않는다.)
SELECT unique_id, e.name FROM Employees e LEFT JOIN EmployeeUNI eu on e.id = eu.id더보기SQL 관련 오늘 알게 된 것(인코딩 부분 대해서는 파이썬것도 포함되어 있음)
- csv파일 import 임폴트 에러 (Can't parse numeric value [*] using formatter)
우선 에러가 난 이유
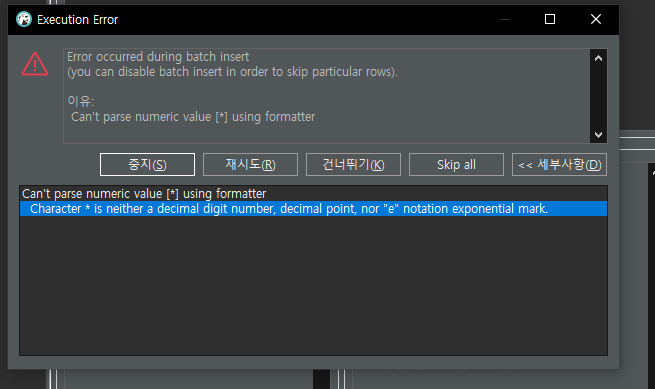
Error occurred during batch insert (you can disable batch insert in order to skip particular rows).
이유: Can't parse numeric value [*] using formatter
Can't parse numeric value [*] using formatter Character * is neither a decimal digit number, decimal point, nor "e" notation exponential mark.
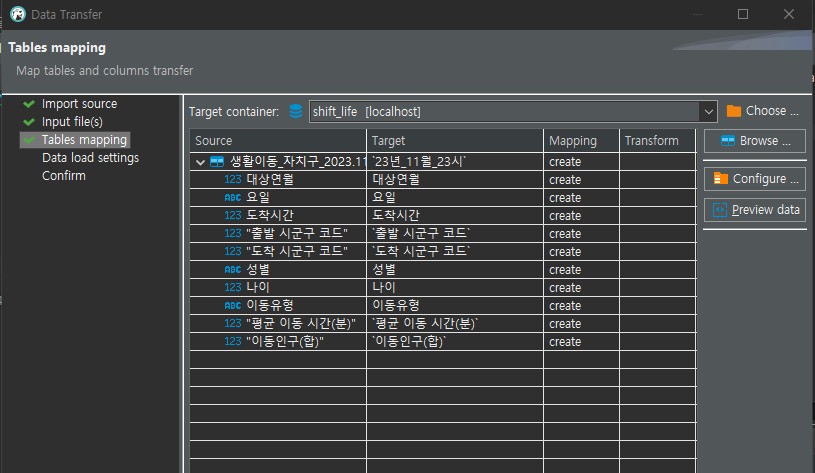
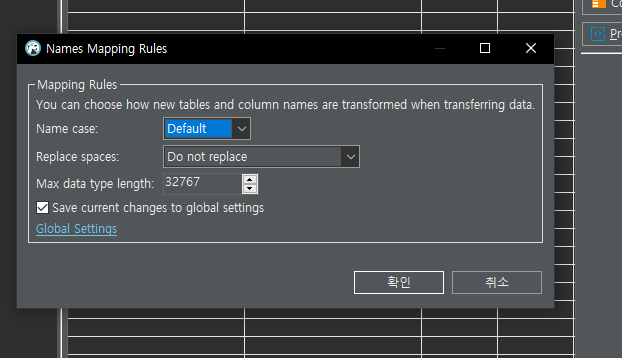
내가 사용한 데이터를 다운 받는 사이트에 적혀있는 내용이 있었다

다음과 같은 것 때문에 이동인구(합) 부분에 *로 되어있는 것이 있어 import할 때 에러가 났던 것이다

심지어 엑셀에서도 *은 특별한 기능을 의미하는 특수문자이기 때문에 그냥 찾기 할떄 shift+8해서 *하면 안되고
ㅁ한자3해서 별*을 입력해 검색해줘야 내가 찾고 싶은 *에 대해서만 찾을 수 있다(다르게 구별이 될지는 모르겠는데 지금 입력하는 것은 ㅁ한자3해서 뒷부분 딱 하나만 그방식으로 하여 별을 입력해주었다) 여담으로 엑셀에서 ?역시 마찬가지라고 한다.
위와 같은 이유 때문에 에러가 났고, 해결 방법은 *로 표시된 부분을 0으로 수정해주는 것인데(3명이하라 3명일 수도 있지만, 사실 전체적으로 봤을 때 매우 적은 인원이 확인되는 것이기 때문에 이정도 보정은 크게 상관이 없을 것이라 판단된다.) csv파일의 크기가 작은 경우는 엑셀로 열어서 직접 바꾸기로 수정해주면 되지만, 파일이 클 경우 행이 100만개를 넘어가 모든 데이터를 볼 수 없기 때문에 DBeaver로 import한 뒤 DBeaver내에서 수정해주어야 했다. 하지만 원래 그대로 Real형식으로 해주면 error가 나기 때문에 우선 varchar형태로 import해주었고, 그 뒤 *을 0으로 수정해 주었는데 처음에는 update가 떠오르지 않아 With구문을 활용한 임시테이블을 통해 Case when을 이용해서 *일 때 0으로 바꾸어 주었으나, 이 임시 테이블을 ALTER TABLE을 통해 컬럼속성을 바꿔주려고하니 에러가 떴고(에러난 사실은 따로 캡처를 하지 못하였다 내가 기억하기론 무슨 버전이 syntax에 안맞다? 그런 내용이 였던 것 같다… 사실 에러창 너무 하도 많이 봐서 헷깔린다..) 그래서 튜터님과 이것 저것 왜 안되는지는 정확히 모르지만 시도하였다.
(여기서 중간 여담으로 *과 %같은 특수문자들은 저마다 기능적인 의미가 포함되어 있는 문자들이기 때문에(검색으로 따로 찾아본 것이 아닌 말로 들은 거라 정확한 용어는 모르겠다)
ESCAPE’ #’를 통해 #뒤에 있는 얘는 그런 뜻이 아니라 문자 그자체로 쓰인 거야 알려주는 것이라고 한다.(*는 select에서 주로 쓰듯 모든? 그러한 의미고, %는 포함하는 그런 의미이다) 그리고 보통 쓰임새가 왠만해선 ‘#’을 사용하여 쓰인다고 한다 다른 것으로도 되는지는 해보시지 않으셔서 모른다고.. (나중에 시간나면 한번 테스트 해보면 좋을듯하다) 앞뒤로 %붙이는 것도 꼭 그렇게 해야만 하는 것인지 여쭤보니 대부분 그렇게 사용해서 아마도 그럴 것 같다고 하셨다. 그래서 만약 포함되는게 아닌 값으로 걔만 딱있는 경우만을 찾고 싶은 경우에는 어떻게 하냐고 여쭤보니 만약 그 걔가 *라면 *로 시작해서 *로 끝나는 조건을 걸어주면 되지 않겠냐고 대답해주셨다 이것도 한번 알아봐야할듯) 그리고 with는 조금 애매하긴 한데 무조건 ()로 된 서브쿼리문?과 붙여서 쓸필요는 없다고 하셨다. 가끔 띄워서 쓰면 안되는 경우 있었던 것 같은데 원인을 좀더 정확히 알아봐야할듯하다
WITH temp AS( SELECT a.`대상연월`, a.`요일`, a.도착시간, a. `출발 시군구 코드`, a.`도착 시군구 코드`, a.`성별`, a.`나이`, a.`이동유형`, a.`평균 이동 시간(분)`, CASE WHEN a.`이동인구(합)` Like '%#*%' ESCAPE '#' THEN 0 ELSE a.`이동인구(합)` END move_pop FROM 생활이동_자치구 a ) SELECT cast(move_pop AS DOUBLE) FROM temp; #ALTER TABLE temp MODIFY COLUMN `이동인구(합)` DOUBLE NOT NULL; #WHERE a.`이동인구(합)` LIKE '%#*%' ESCAPE '#'; SELECT a.`대상연월`, a.`요일`, a.도착시간, a. `출발 시군구 코드`, a.`도착 시군구 코드`, a.`성별`, a.`나이`, a.`이동유형`, a.`평균 이동 시간(분)` , cast(a.`이동인구(합)` AS DOUBLE) "이동인구(합)" FROM 생활이동_자치구 a; UPDATE `생활이동_자치구` SET `이동인구(합)` = 0 WHERE `이동인구(합)` LIKE '%#*%' ESCAPE '#'; ALTER TABLE `생활이동_자치구` MODIFY COLUMN `이동인구(합)` DOUBLE; SELECT * FROM test;update는 테이블에서 일정 컬럼의 값을 수정시켜주는 명령어?이다. 대신 where 꼭 잊어먹지 말도록하자! 그런데 저방법도 alter는 먹히지 않아서 결국 원하는대로 형식 바꾼채 출력되게 한 뒤, export시켜줘서 그것을 저장하고 다시 새로 import시켜주는 방식으로 해결하였다 매우 번거로운 간접적인 방법이였지만, 너무 해결이 안되기도 했고(거의 1시간 넘게 튜터님이랑 같이 머리 싸매고 고민하고 시도하였다..) 번거로워도 일단 확실히 해결되는 방법이기에 결국 저렇게 해결해주었다. (오늘 같이 고생해주신 김인수 튜티님께 죄송하고 감사드린다!(9시 퇴근이신데 거의 9시 50분다되어서 끝이 났다...ㅠㅠ))
- 한글, 특수문자, 띄어쓰기가 이름에 포함된 테이블 불러올 때
무슨 형식 키보드 였는지 까먹었는데 째든 현재 내가 쓰고 있는 키보드 형태중 1옆에 있는 `를 앞뒤로 붙여주면 된다. 인용 식별자 backtick이라고 한다 그런데 사실 테스트 해본 결과로는 일반적인 쿼리들을 작성할 때 띄어쓰기나 특수문자 포함된 경우는 써줘야하지만 그렇지않은 한글의 경우는 인코딩을 euc-kr로 해줘서 그런지 모르겠지만 그냥 써줘도 정상적으로 잘 작동했던 것 같다.
- 한글 포함 되어 있어서 (컬럼명?)등 한글 깨지거나 에러날 때 인코딩 euc-kr로 하면 됨! 그 외 인코딩관련
다른 분이 팁으로 알려주신 방법
import pandas as pd file_path = '1.csv' # 파일 위치 # 인코딩 테스트 encoding_list = ['ascii', 'big5', 'big5hkscs', 'cp037', 'cp273', 'cp424', 'cp437', 'cp500', 'cp720', 'cp737' , 'cp775', 'cp850', 'cp852', 'cp855', 'cp856', 'cp857', 'cp858', 'cp860', 'cp861', 'cp862' , 'cp863', 'cp864', 'cp865', 'cp866', 'cp869', 'cp874', 'cp875', 'cp932', 'cp949', 'cp950' , 'cp1006', 'cp1026', 'cp1125', 'cp1140', 'cp1250', 'cp1251', 'cp1252', 'cp1253', 'cp1254' , 'cp1255', 'cp1256', 'cp1257', 'cp1258', 'euc_jp', 'euc_jis_2004', 'euc_jisx0213', 'euc_kr' , 'gb2312', 'gbk', 'gb18030', 'hz', 'iso2022_jp', 'iso2022_jp_1', 'iso2022_jp_2' , 'iso2022_jp_2004', 'iso2022_jp_3', 'iso2022_jp_ext', 'iso2022_kr', 'latin_1', 'iso8859_2' , 'iso8859_3', 'iso8859_4', 'iso8859_5', 'iso8859_6', 'iso8859_7', 'iso8859_8', 'iso8859_9' , 'iso8859_10', 'iso8859_11', 'iso8859_13', 'iso8859_14', 'iso8859_15', 'iso8859_16', 'johab' , 'koi8_r', 'koi8_t', 'koi8_u', 'kz1048', 'mac_cyrillic', 'mac_greek', 'mac_iceland', 'mac_latin2' , 'mac_roman', 'mac_turkish', 'ptcp154', 'shift_jis', 'shift_jis_2004', 'shift_jisx0213', 'utf_32' , 'utf_32_be', 'utf_32_le', 'utf_16', 'utf_16_be', 'utf_16_le', 'utf_7', 'utf_8', 'utf_8_sig'] for encoding in encoding_list: worked = True try: df = pd.read_csv(file_path, encoding=encoding, nrows=5) except: worked = False if worked: print(encoding, ':\\n', df.head()) #정현석 튜터님이 알려주신 코드!
오늘은 거의 사실상 개인공부 아예 못하고, 코드카타도 사실상 못풀었으며, 프로젝트 관련 회의가 반이였고, 나머지 데이터 처리할 때 에러 해결하는 것이 나머지 반의 3/4였던 것 같다
그래도 몰랐던 사실들을 (원하진 않았지만) 많이 알게되어서 살짝 뿌듯하다 특히 임포트 안되는 이유는 나혼자 검색한 것도 거의 안 나오다 싶이해서 이것저것으로 추론하다가 원인을 알고 해결한 것이라 더욱!
프로젝트 자체는 그래도 아직 순탄하다고 볼 수 있을 듯하다.
'스파르타 > TIL(Today I Learned)' 카테고리의 다른 글
2024-01-15 (2) 2024.01.15 2024-01-13~2024-01-14 (1) 2024.01.15 2024-01-11 (2) 2024.01.11 2024-01-10 (0) 2024.01.10 2024-01-09 (2) 2024.01.09