-
2024-02-01스파르타/TIL(Today I Learned) 2024. 2. 1. 23:30더보기
SQL 코드카타
Top Earners(SQL)(max, count, from 서브쿼리, where 서브쿼리, hackerrank는 with가 안되나?)
한 직원의 총 수입은 월급*달수 로 구하는데, 가장 큰 총수입 금액과 그 금액을 받는 직원수를 구하는 문제이다
WITH total_earning AS ( SELECT e.employee_id, e.name, e.salary * e.months tot_earn FROM employee e ) SELECT count(*) FROM total_earning te WHERE te.tot_earn = (SELECT MAX(te2.tot_earn) FROM total_earning te2);ERROR 1064 (42000) at line 4: You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'total_earning AS ( SELECT e.employee_id, e.name, e.' at line 1 #라고 에러가 떳다결국 with안쓰고 서브쿼리 써서 해결하였다
SELECT MAX(te.tot_earn), count(*) FROM (SELECT e.employee_id, e.name, e.salary * e.months tot_earn FROM employee e) te WHERE te.tot_earn = (SELECT MAX(e2.salary * e2.months) FROM employee e2);확인해봐야겠지만 아마 여기선 with 없는 듯하다..-> 혹시나 해서 질문드려서 튜터님이 확인해보니 mysql8.0이전에는 with가 없었다고 한다 아마 hackerrank는 옛날 플랫폼이라 낮은 버전을 쓰지 않을까 추측되며 따라서 with가 되지 않은 것 같다
Weather Observation Station 13(SQL)(TRUNCATE 버림, sum)
Weather Observation Station 13 | HackerRank
STATION에서 38.7880보다 크고 137.2345보다 작은 값을 가진 북위(LAT_N)의 합을 조회하는 문제이다. 이때 답을 소수점 4자리로 자른다.
SELECT TRUNCATE(SUM(s.lat_n),4) FROM station s WHERE s.lat_n > 38.7880 AND s.lat_n < 137.2345저런 식으로 실수를 초과 미만으로 조건 주면 between못쓰나? ->질문드려보니 못쓰는게 맞다고 하셨다
Weather Observation Station 14(SQL)(TRUNCATE 버림,max)
Weather Observation Station 14 | HackerRank
STATION에서 137.2345보다 작은 값을 가진 북위(LAT_N)중 가장 큰값을 조회하는 문제이다. 이때 답을 소수점 4자리로 자른다.
SELECT TRUNCATE(MAX(s.lat_n),4) FROM station s WHERE s.lat_n < 137.2345더보기SQL+머신러닝 관련 질문
SQL관련 질문한 것은 총 3개를 질문하였는데 간단해서 2개는 오늘 내용관련이라 바로 적으면서 적어주었고 하나만 간단히 적겠다
1월31일 세번째 문제에서 했던 내용 관련해서 문제내용과 같이 할일은 없을 것으로 당연히 예상됬는데 그외 일부에 대해서 특정 숫자나 문자를 제외하는 일에 대하여 실무에서 하는 경우가 있는지 여쭤봤는데 역시 거의 없다고 하셨다 해봣자 스페이스(공백)이나 전화번호에서 -정도 제거하는게 있을까하고 나머진 진짜 사실상 없다봐도 된다고 하셨다, 그리고 주로 반올림을 쓸 것 같은데 실무에서 올림이나 버림도 사용하는지 여쭤봤는데 케바케일듯하며 주로 가이드라인이 있기에 가이드라인을 따르면 되지만 역시 반올림을 주로 쓰며 튜터님은 반올림외 올림이나 버림을 쓰셨던 적이 한번도 없으셨다고 하셨다
머신러닝관련해서
로지스틱 모델 부분에서 워닝떴던 것이 있었는데(이전 질문에도 여쭤봤던 것인데)
경고출력문구도 다 복사를 해두었지만 길기 차지만 할듯하여 블로그에는 생략하도록 하겠다
y_true = titanic_df['Survived']으로 수정하거나 아니면 에러코드 그대로 복사해서 붙여넣어보면 아마 바로 해결방안 나올듯 한데 추측으로는 reshape나 label로 하라고 나올 것으로 예상된다고 하여 감안해서 직접 찾아보면 될듯하다(현재는 개인과제라던가 더 우선순위가 높다고 생각되는 부분들이 있어서 그 부분들을 먼저하고 나중에 찾아볼듯하다)
seaborn barplot 에러바 그려지는 기준?, 설정?이 어떻게 되는지 궁금해서 여쭤봤는데
대강 신뢰구간이라고 하는 통계적으로 추정한 것 표시해준것이며 (따로 뭘 설정해주는 것이 아닌 메소드에 통계적으로 바로 계산되도록 코딩되어 있는 것이라고 한다)
에러바가 클수록 자료가 튄다고 생각하면 된다고 한다
scatterplot에서 겹친 것 확인하고 싶을 때 해볼 수 있는 방법에 대해 생각한 부분에 대해 가능할지 여쭤봤다
scatterplot에서 겹친 것 확인하고 싶을 때 선으로 가면 히스토그램으로 생각 할 수 있을 듯한데, 그럼 y축이나 x축에 대해 한 값으로 고정시키고 히스토그램 그리는 방식도 가능한지?
아마 조건문으로 boolean해주면 가능할듯한데 ->충분히 가능할듯함, 그려서 해보면 될듯
그리고 위의 것을 합치면 히트맵처럼 볼 수 있을 듯한데 히트맵으로 겹치는 것 등의 분포가 확인이 가능할지?
->메소드에서 지원해줄지는 확인해봐야할듯
추가로 scatterplot자체에서 겹치는게 많으면 하이라이팅해주는게 있을수도 있으니 확인해보기(이러한 경우가 많았기에 편의성을 위해 옵션으로 추가해줬을 수도 있다고 생각되어서)
위에서 로지스틱과 유사한 맥락으로 파악되는데 레이블인코딩부분에서 워닝이 떴었는데 이유에 대해 여쭤봤다
(마찬가지로 워닝코드는 길어서 블로그에는 생략하도록 하겠다)
이것도 df랑 series차이 문제인가?
le.fit(titanic_df['Sex']) 로 적어주면 될지? -> 어레이라이크라 크게 에러는 안날듯함, 하지만 직접 해봐야 알듯
자세한 것은 직접 독스찾아보는게 좋을듯 하지만 fit에는 가능한 df로 들어가는게 맞을듯하고 계속 비슷하게 경고가 나는데 데이터 형태의 차원 문제로 자세히는 이해가 안되었기에 모아서 관련해서 찾아서 공부해보면 이해가 잘 갈듯하다(이부분에 대해서 추가 공부는 마찬가지로 우선순위 높은 부분들 부터 먼저하고 할예정이다)
컬럼명 get~으로 안하고 위의 카테고리로 해줘도 되지 않는지? (onehot encoding)
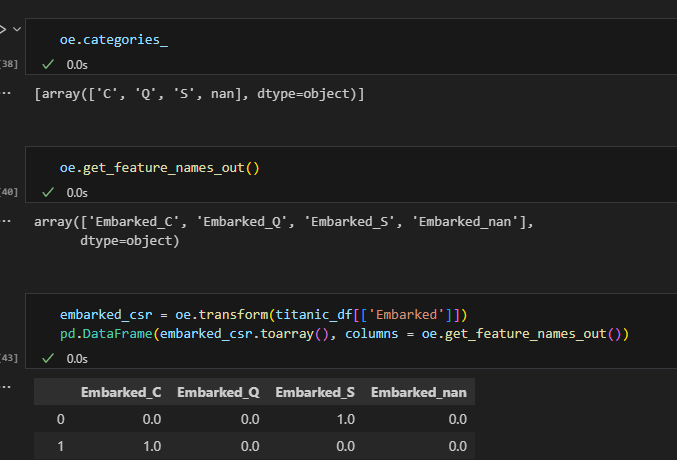
->아마 nan가 문자열이 아니라서 nan형 자료형태라 아마 에러날 가능성이 높음
일단 테스트는 직접해볼필요있을듯 그래서 원래 문자열로 들어가는게 맞아서 get_feature_names_out()로 해주는게 맞을 것으로 생각이 되기는 한다
IQR에서 75%의 의미에 대해 확인해봤는데 내가 예상한대로 하위로부터 75%에 해당하는 즉 상위 25%의 의미를 가지고 있는 것이 맞다고 하셨다
문서 한번 봐야할듯한 것 (mmsc)관련해서 함수들이 있길래 혹시 아시는지 여쭤보았다
MinMaxScaler , MinMax_scale이라는 것도 있던데 그건 먼지?
값자체를 스캐일링 해주는 듯함
스캐일은 함수고, 스케일러는 클래스를 가져오는듯 이러한 차이를 가지고 있는 것으로 독스를 통해 확인 후 알려주셨다
family는 정규분포처럼 되어있지 않은데 minmax써도 상관없는 이유?
강의 중에 값이 그리 크지 않으니 라고 하셨는데
분포가 왼쪽에 치우쳐 있고 10을 넘는 값이 이상치처럼 있는데 sd을 쓰지 않고
정규화를 하신 이유?

->있을 수 있는 듯해서 sd써도 성능 그렇게 차이 안날듯
구분은 이상치 유무로 구분 초점
분포에 대해서는 구분하는 것보다 종모양이면 물론 좋기는하지만 스쿼드되면 로그로 처리하는 것이 더 좋은 결과를 보일 듯함
함수안에서 import하는 것관련
다른 튜터님한테도 비슷한 것을 여쭤본적이 있었는데 뭔가 자신없는 듯이 조금 불확실하게 느껴져서 겸사겸사 import 같은것 여러번 해도 되는지 여쭤보았다
미리 import할 때 한번에 해주는게 낫지 않은지?
import여러번해줘도 사실 그렇게 영향이 없을 것 같기는 한데 아예 영향이 없다고 무시해도 좋을 만큼 적은지? 상관없음!
밖에 쓰는게 좋기는 한데 함수채로 불러오는게 좋을 듯 함→추가 체크 하면 좋을듯
(그리고 튜터님의 경우는 인터프리터?였나 ipynb파일 처럼 줄글로 바로바로 되는 경우가 아닐 경우 py등의 스크립트로 짤 경우 함수를 불러오면 바로 문제없이 자동적으로 임폴트되서 실행 가능하도록 해주는게 좋다고 생각되셔서 주로 저런식으로 함수안에 import하는 방식으로 하신다고 하셨다)
살짝 겹칠 수도 있는 부분인데 함수안에 모델fit넣어뒀을때 여러번 fit해도 상관없는지?
함수실행했다가 또 추가로 .describe()붙이고 다시 실행하면 이미 fit된 것 또 fit하는 것이 아닌지?
또 해도 상관이 없는지?
fit을 다시 해주면 기존 학습했던 것을 날리고 새로이 학습을 하는 것인지 아니면 학습한 것에 추가로 학습해서 둘을 합쳐주는 것인지?→논리적으로봤을때 덮어쓰기(기본것 날리고)
처음에 초기화로 가중치들 0으로 되어있었을 테니 그렇게 생각하는 것이 맞지 않겠냐고 말씀해주셨다(확실한 것은 팩트 체크해볼 필요성은 있으나 같은 데이터에 대해서 할 경우는 심각하게 엄청 신중히 생각할 필요는 없을 듯함)
그리고 다른 데이터셋 A로 학습한 모델을 데이터셋 B에 대해 학습시켜줄 때는 새로 모델을 만들어서 하라고 하신 이유가 기존 학습한게 날라가기 떄문에 그럴 것이라고 생각이 된다
labelencoding은 또 왜 두개 한번에 학습시키면 에러나는지?
mm_sc의 경우는 2개로 한번에 학습이 되었는데 le는 안되는 것인지? 독스뒤져보는게 좋을지도?
->확실한 것은 docs확인해보는게 정확할듯 하지만 일단 메소드 설계상으로 le는 두개 동시에 학습하는게 안되도록 되어 있는 것으로 추정됨
함수를 통해 리턴해준 df에서는 info로는 oe로 해준 컬럼이 추가되었는데 다시 df확인해볼때는 해당 컬럼 없었는 이유? 변수 저장되는 주소 이런거랑 관련있을 듯한데 좀더 고민해볼 필요는 있을듯 해결한 방식으로는 함수를 df=함수 해서 리턴결과를 다시 저장해줬음 안에서 df[]=~해준 건 추가된 채로 반영됬는데 concat만 반영이 되지 않은 것으로 보이는데 concat은 먼가 다른거 같은데 어떤 점이 달라서 이런 결과가 나타나는지 궁금
-> 지역변수와 글로벌변수 차이로 인하여 이런 문제가 발생하였을 것으로 거의 확실하다 할 수 있을 정도로 추정됨
자세한 것은 지역변수와 글로벌변수 좀더 공부해보기
영상 끊고 다시 다음 영상으로 시작하면서 윗부분 transform df에서 시리즈로 형태를 바꿔주셨는데 이유가 무엇인지?(아마 워닝 뜬 부분때문에 그렇게 하신듯한데) 그리고 le는 그렇게 해주는게 해결되는데 oe는 해결되지 않는 이유?
->csr변환되는 조건 등 확인하면 좋을듯 (csr이 중간에 df화 해서 하는 과정부분에서 뭔가 워닝나게 만드는 것이 있는듯)
이부분은 나중에 따로 더 찾아보기
sub_df.to_csv('./result.csv')
표기법 의미?
./의 의미가 궁금함 전에 해봤던 기억으로는 굳이 안붙이고 result.csv만하면 해당 파일 있는 경로에 저장 해두던 것으로 기억하는데 저렇게 해주는 것이 더 좋은지?
-> 현재경로에 저장한다는 의미 ,
편한대로 하면되긴 하는데 공식적으론 상대경로나 절대경로 둘중하나 적어주는 것이 좋음
상대경로와 절대경로에 대해 알면 좋음
이건 상대경로로 적은것
GridSearchCV관련해서 cv옵션 의미?
cross-validation generator 의 의미로(조금 길게 느껴져서 ) 교차검증 처럼 알아보기 해주는 것 몇개로 나눠서 학습하고 테스트하고 바꿔가면서 할지 설정해주는 것(파라미터의 수와 값이 달라도 된다고 하셨음, 확실히는 이해안되서 직접해봐야 알 수 있을듯)
test 데이터에 대해 전처리 동일하게 해줄 때
변수생성
이상치 제거? →테스트에 대해선 안해주는게 맞는지? 해주면 좋은데, 실제 회사 예측해야하는 데이터에는 이상치여도 넣어서 평가해야할 수 있음
미리 까볼 수 없는 것이기 때문에 상황에 따라 달라짐 이상치를 임의의 상황으로 따로 구분할 수도 있음 →train에선 없던 경우면 있던 경우로 대치할 수도 있음
결측치 처리 →동일방식으로 처리해준다는 의미로 받아드려지는데 맞는지?
그리고 결측치 수치는 평균(얘는 적당한 대표값이라고 볼 수 있는 것으로 다 가능할 듯함), 범주는 최빈 말고 다른 방법으로 처리하는 방법 또 있는지?
수치형 변수 전처리 스케일링
sd방식이면 평균이랑, 표준편차를 train것을 사용해 해준다를 의미 맞을지?
mm방식이면 최대,최소값을 train것을 이용해서 해준다는 의미가 맞을지?
범주형 변수 전처리 인코딩
인코딩 자체는 그냥 train에서 인코딩한 것과 동일한 방식으로 해준다 일듯
(이상치 부분 제외하고는 이해한대로 생각한게 다 맞았음)
추가로 질문으로 다 적기에는 애매해서 의사결정나무가 쓰이는 이유정도만 추가로 작성해주도록 하겠다
의사결정나무는 해석력이 좋아서 쓰는 것 트리의 갈래 나눠질떄 어떻지 확인가능해서 그런점이 좋아서 쓰임
런데 모델 학습하고 위에서 추가로 수정해줬을때 이런 부분 변수초기화 안해주고(재시작)
그냥 바로 모두 실행만 눌러줘도 상관 없는지?(원본 df을 건드렸다던가하는 것이 아니라 모델에 관련해서라면?)
→변수값이 잘못할당 되어있는 것이 아니라면 안해줘도 상관은 없으나 가능하면 재시작한 뒤 모두 실행하는 것이 좋다고 하심
뒷부분으로 갈수록 가셔야하는 시간이 다되거나 살짝 오버해버려서 급하게 물어본 경향이 조금 있었다..ㅠ
그리고 블로그 기록에는 이번에도 마찬가지로 블로그에 적기에 조금 애매하다 싶은 부분은 다 제외하고 적었기에 실제 물어본 질문보다 적은 일부만 작성해주었다
오늘 SQL코드카타는 한문제가 with가 안 될 것이라곤 예상도 못해서 살짝 오래 걸린 것 제외하고는 크게 별 무리 없이 지나갔다
그리고 머신러닝강의를 오늘 다 들었는데 대체로 이해가 가능했지만 뒷부분 갈수록 특히 딥러닝부분은 살짝 이해가 안되는 부분도 좀 있었지만 흥미가 좀 가는 듯하여 여유가 날 때 추가로 공부해보고 싶은 마음이 생겼다
그리고 심화강의부분은 듣다가 의문가는 부분이 좀 많이 생겨서 질문을 많이 드렸는데 살짝 급하게 물어본 감이 있어서 속시원하게 확실히 여쭤보지는 못한 것 같아서 그부분이 조금 아쉬웠다
'스파르타 > TIL(Today I Learned)' 카테고리의 다른 글
2024-02-03~2024-02-04 (0) 2024.02.05 2024-02-02 (1) 2024.02.02 2024-01-31 (2) 2024.01.31 2024-01-30 (0) 2024.01.30 2024-01-29 (1) 2024.01.29