-
2024-01-25스파르타/TIL(Today I Learned) 2024. 1. 26. 00:06더보기
SQL 코드카타
185. Department Top Three Salaries(SQL)(윈도우 함수, dense_rank, 각 그룹별로 상위 3개씩만 출력하기(여기서는 부서별로 월급 상위 3위까지))
https://leetcode.com/problems/department-top-three-salaries/description/
각 부서별로 가장 많은 3개의 unique 월급을 받는 직원을 출력하는 문제이다(그냥 금액을 기준으로 큰것 3개에 해당하는 받는 직원 모두 출력하는 의미이다)
WITH rk_salary AS ( SELECT e.id, e.name, e.salary, e.departmentId, DENSE_RANK() OVER(PARTITION BY e.departmentId ORDER BY e.salary DESC) rk FROM Employee e ) SELECT d.name Department, rs.name Employee, rs.salary FROM Department d LEFT JOIN rk_salary rs ON d.id = rs.departmentId WHERE rs.rk <= 3윈도우 함수 dense_rank를 이용하여 해주었다
쿼리에 대해 간단히 설명하면 우선 employee 테이블에 대하여 각 원래 있던 컬럼들에 추가해서 dense_rank 윈도우 함수를 이용하여 부서를 기준으로 나누고, salary를 내림차순으로 순위를 매겨 rk로 추가해주었다 그런 뒤 그러한 테이블을 임시테이블 rk_salary로 선언하였다
그뒤 department 테이블과 rk_salary테이블을 d.id와 rs.부서id로 공통컬럼을 가지게 left join해주었으며 그중 rs.rk가 3이하인 것들만 필터링해서 나오도록 해주고 부서이름, 직원이름, 월급이 표시 되도록 해주는 쿼리이다.
제일 간단해 보이는게 윈도우 함수 이용해서 순위 매겨주고 그 순위에 따라 출력해주는 방식이 간단해보여 그리 시도했으나 윈도우 함수를 써서 너무 성능이 떨어질지 원래 어제 질문해보려고 했는데 빠트려서 이것도 추가해서 같이 여쭤보면 좋을 듯하다 그래서 질문을 드렸는데 아래 질문한 내용으로 다시 서술하도록 하겠다
아래는 다른사람 쿼리이다
SELECT d.Name as Department, e.Name as Employee, e.Salary as Salary FROM Department d, Employee e WHERE ( SELECT COUNT(DISTINCT Salary) FROM Employee WHERE Salary > e.Salary AND DepartmentId = d.Id ) < 3 AND e.DepartmentId = d.Id ORDER BY d.Id, e.Salary DESC;join아니고 그냥 가져와서 서브쿼리로 해준듯한 방식 그런데 그냥 from에서 여러개 가져오는 건 이게 괜찮은 방식인지 궁금해서 질문했는데 질문에 대한 해답은 아래 질문한 내용으로 아래 다시 서술하도록하겠다
1667. Fix Names in a Table(SQL)(concat, upper, substr, lower, 일부 대문자, 일부 소문자로 변환, length와 char_length, left, right)
https://leetcode.com/problems/fix-names-in-a-table/description/
테이블에서 유저이름을 첫글자만 대문자로 나머지는 소문자로 표시되게 변경하는 문제이다
SELECT u.user_id, CONCAT(UPPER(SUBSTR(u.name,1,1) ),LOWER(SUBSTR(u.name,2))) name FROM Users u ORDER BY u.user_id쿼리에 대해 간단히 설명하면 우선 User 테이블에서 데이터를 가져와 user_id와 substr를 이용해 name에서 첫글자부터 한개를 가져와 uppper로 대문자로 바꾸고, substr를 이용해 name에서 두번째 글자부터 끝까지를 가져와 lower로 소문자로 바꾼 뒤 concat을 이용하여 합쳐주었으며 마지막으로 user_id로 오름차순 정렬하여 출력하게 하는 쿼리이다.
아래는 다른 사람의 쿼리이다
SELECT user_id, CONCAT(UPPER(SUBSTR(name, 1, 1)), LOWER(SUBSTR(name, 2, length(name)))) AS name FROM Users ORDER BY user_id; # CONCAT(A, B) # LOWER(str), UPPER(str) # SUBSTR(name, start_index, end_index) # length(name)length라는 함수도 있는 줄 처음 알았다 파이썬의 len같은 녀석인듯하다
그런데 엄밀히 따져보면 length(name)-1해줘야 정확히 끝나는 갯수에 맞게 끝나는게 아닌가 하는 생각이 들었다
그런데 저런식으로 몇개를 지정해주는게 조금더 연산이 적게 걸리는 것인지도 궁금하다 그래서 질문을 드렸는데 마찬가지로 아래 질문한 내용에 모아서 서술하도록 하겠다# Write your MySQL query statement below SELECT user_id,CONCAT(UPPER(SUBSTR(name,1,1)),LOWER(SUBSTR(name,2,length(name)))) AS name FROM Users ORDER BY user_id; # SUBSTR(string_name , start_index ,end_index) # second method SELECT user_id, concat(upper(LEFT(name, 1)), lower(RIGHT(name, length(name)-1))) as name FROM users ORDER BY user_id; #RIGHT(name_of_string, no_of_charachters)left, right쓰는 방식이다
1527. Patients With a Condition(SQL)(like, substr, locate, 한 컬럼에 띄어쓰기(’ ‘)를 통해 여러 값이 들어가 있을 때 해당 컬럼에 대해 특정 값 조회하여 출력하기)
https://leetcode.com/problems/patients-with-a-condition/description/
테이블에서 상태에 DIAB1를 가지고 있는 환자를 출력해주는 문제이다.
SELECT p.patient_id , p.patient_name, p.conditions FROM Patients p WHERE p.conditions LIKE '%DIAB1%'처음에는 단순히 DIAB1가 포함된 경우로 하였는데
| patient_id | patient_name | conditions | | ---------- | ------------ | ---------- | | 1 | Daniel | SADIAB100 |다음과 같이 띄어쓰기 안하고 붙어있는 경우에 대해서도 필터링 되어 나와서 제거를 해줘야할 필요성이 있었다
SELECT p.patient_id , p.patient_name, p.conditions FROM Patients p WHERE p.conditions LIKE '%DIAB1%' AND SUBSTR(p.conditions,LOCATE('DIAB1',p.conditions)-1,1) =' '따라서 DIAB1의 글자위치를 locate를 통해 찾은뒤 위치에서 바로 앞글자가 띄어쓰기인지 확인하는 방식으로 만족하는 경우만 출력하도록 추가해주었다
아래는 다른사람 쿼리이다
# Write your MySQL query statement below SELECT * FROM Patients WHERE conditions LIKE ('% DIAB1%') OR conditions LIKE ('DIAB1%');아 띄어쓰기까지 해준 거구나 처음에 그냥 %DIAB1%이랑 DIAB1%인줄 알았는데 저런시기으로 바로 띄어쓰기 포함해서 검색할 수 도 있다는 것을 알 수 있었다
더보기오늘 질문한 부분
(크게 의미 없을만한 부분이나, 만족할만한 답변을 얻지 못하였다고 생각 되는 부분은 제외하였다)
우선 SQL 관련하여 질문 했던 부분이다 어제 질문하려했지만 깜빡하고 빠트린 부분인데 윈도우 함수 사용 여부라고 할까? 이전 특강부분에서 윈도우 함수는 연산이 많이 잡아먹으니 되도록 쓰지말라고 하셨었는데 쓰는게 더 빠른 경우도 있는지에 대하여 여쭤보았다
여러가지 케이스에 대해 들고가서 여쭤보았는데 결론적으로
서브쿼리로 간단히 풀리는 문제는 굳이 윈도우 함수 쓸필요없음
하지만 서브쿼리로 복잡하게 여러개 써서 풀어야하는 문제의 경우 윈도우 함수 하나로 간단히 풀린다면 윈도우 함수 하나 쓰는게 이해도 잘되고 좋을 경우가 많을 듯함
이라는 결론을 내릴 수 있었다그리고 substr관련하여 글자 끝까지 가져올 경우 몇개를 가져올지 적어주는 것에 관하여 적어주는 것이 좋은 것인지 여쭤보았다 여쭤본 결과로는 안적어주는게 좋을 듯하다고 하셨다 오히려 몇개로 끝날지 값별로 길이도 다를 수 있어서 적어주는게 오히려 더 연산에 안좋을 가능성 높다고 생각하신다고 얘기하셨음(물론 내가 중간에 length같은 함수로 적어준 경우를 봤다고 말씀도 드렸다 하지만 그 얘기까지도 다 들어보시고 굳이 적어주지 않아도 괜찮으며 오히려 안적어주는게 더 좋을 것 같다고 말씀해주셨다)
그리고 from에 join 안쓰고 여러 테이블 가져오는 경우에 대해서도 여쭤 봤는데 특별한 몇몇 상황 예를 들어 데이터가 너무 커서 join해서 가져오는게 더 나은 경우에는 별로 일듯하지만 그외는 직관적이고 깔끔해서 오히려 이 방식이 가능하다면 사용하는 것이 좋아보인다고 하셨다(튜터님도 이런 방식이 되는 줄 처음 아셨다고...)
그리고 과제 관련해서 등 여쭤본 질문 내용들이다
dataframe에서 값에 접근 하는 방식이 df['컬럼']과 df.컬럼 두가지 방식이 있는데 이 두방식의 차이에 대하여 여쭤보았다. 우선 df['컬럼'] 방식은 function을 사용하는 방식이며, df.컬럼은 메소드로 사용하는 방식이라고 하셨으며, 내가 물어본 상황에 대한 경우는 function을 사용해서 쓰는 방식이 정석이라고 하셨으며, 메소드로 쓰면 컬럼명이 띄어쓰기로 되어 있다던가 하는 몇몇의 경우에는 아예 안될 수도 있어서 사용시 주의를 해야한다고 하셨다 그리고 처음에는 나의 질문의도를 조금 잘못 이해하셔서 다른 정보를 주셨는데 메소드로 사용하는 방식과 function으로 사용하는 방식이 있는데 보통 메소드가 클래스 내부에 있는것이라 전문적으로 다루기에 최적화가 되어있을 것이라고 보셨으며 function은 그렇지 않은 경우도 있을 것이라고 하셨다(아마 외부에서 받아서 쓰거나 하는 경우도 있어서..? 이부분은 명확히 듣고 이해하지 못하였다..ㅠ) 그래서 보통 둘다 되는 경우는 메소드가 낫지만 어디까지나 상황에 따라 달라 확인을 해줄 필요가 있다고 하셨다
그리고 전에 강의에서 day of week 즉 dow는 보통 일요일을 0으로 하는 경우가 많다고 하셨는데 이번에 pandas.dt.day_of_week를 쓸 경우 직접 확인해본 결과 월요일을 0으로 하는 것을 확인했다 그래서 기본적으로 원래 이런 것인지 아니면 따로 옵션으로 변경이 가능한 부분인지 여쭤보니 이부분은 내가 직접 pandas day of week를 검색하여 docs를 읽어보는 편이 좋을 것 같다고 하셨다
그리고 추가로 dt는 pandas하위에 존재하는(?) 것으로 (아마 메소드..?) date관련해서 쓰겠다하면 사용하게 된다고 생각하면 될 것 같다고 말씀하셨다. 또 추가로 내가 .dt를 생략하면 어떻게 되냐고 궁금해서 여쭤보니 day_of_week는 dt하위에 정의되어 있는 메소드라 .dt를 생략하면 작동이 아예 안될 것이라고 말씀해주셨다
그래서 오늘은 시간이 좀 늦게 되어서 추가로 dow에 관련하여 docs를 찾아봐야할 듯하다
그리고 df.groupby(~)는 어떤 형태로 데이터가 나오게 되는 것인지에 대하여 여쭤봤는데
왜냐하면 print나 display나 그냥 vscode자체 기능으로 인자를 확인하는 방법 어느 것을 써도

이런식으로 표시 되었기 때문이었으며, 튜터님이
for day_of_week, group in df.groupby("day_of_week"):print(day_of_week)display(group.head())를 쳐서 확인해보면 알 수 있을 것 이라고 하셔서

위 와 같은 방식으로 각 day_of_week에 해당 되는 테이블?이 프린트 되었다 이게 for in 쓰기전에는 뭔가 좀 복잡한 다른 형태로 되어있다가 for in으로 쓰면 저런 형태로 분리된다고 하셨던 것 같다
그리고 또 원본 데이터를 대체하는 부분에서 그냥 = 을 사용하여 안하고 concat으로 해주신 이유에 대하여 여쭤봤는데 리스트 안에 [df1, df2, …]이런 식으로 들어있을 것으로 예상되는데 그래서 concat을 써주신건지 여쭤보았는데 맞다고 하셨다 아마 저런 형태이기 때문에 concat말고 다른 방식으로는 되는 것이 없는 것으로 알고 계신다고 하셨다
그리고 관련지어 df가 어떻게 되어있는 형태인지 여쭤보며 [[a,b,c],[1,2,3]] 이런 단순한 리스트 안에 리스트들이 있는 배열 형태라고 생각하면 될지 여쭤봤는데 그런 단순한 구조로 되어있는 것이 아닌 내가 처음 들어 잘모르는 어떤 복잡한 것으로 되어있다고 하셔서 자료구조를 따로 공부해야 알 수 있다고 하였다. 그리고 내부구조를 확인할 수 있는 방법이 없을지도 여쭤보았지만 print등이 시스템적으로 그렇게 나와서 보이도록(array([1,2,3],[a,b,c])같은 느낌) 되어있어 그렇게 나오는 것이고 그래서 실제 구조가 그런 단순한 구조가 아니며, 또 시스템적으로 설계가 그렇게 되어있어 따로 내부구조를 바로 볼 방식은 없고 직접 코드를 까서 보는 방법 밖에는 없을 것이라고 말씀해주셨다
그리고 파일을 불러와서 메모리 최적화 하는 방법에 대하여도 여쭤봤지만 강의시간에 간단히 말씀해주신 안쓰는 컬럼날리는 것 외에도 데이터의 형식을 바꿔주거나 하는 여러 방식이 있지만 그부분은 나중에 스파크를 배울 때 거기서 자세히 다룰 예정이라고 하셨다
그리고 전처리를 하는 역량을 늘릴려면 어떤 식으로 공부를 해야할지와 성능 확인법에 관하여 여쭤봤는데
우선 지금 질문하듯이 이런 방식들로 접근 계속하면 도움될 것이라 말씀하셨고, 또 추가적으로 자료구조를 정식으로 공부하면 좋을 것 같다고 하셨다. 성능관련하여 체크하는 방법으로는 아무래도 내가 막 0.0000~초 이렇게 나와서 확인이 힘들다고 말씀드렸던 부분이 있어서 그런지 데이터를 늘리고 여러번 돌리는 식으로 테스트 해보는 것을 많이 한다고 말씀해주셨으며, 사실 작은 데이터에 있어서는 어떤 코드가 빠르지만 큰 데이터나 다른 상황에서는 다른 코드가 빠를 수 있기 때문에 특정상황 하나 이겼다고 이 코드가 더 성능이 좋다 판단하기는 힘들다고 하셨으며, 그래서 왜 이런 결과가 나왔는지(어느 것이 결과가 더 빨리 나오는가) 까지 알아야하기 때문에 시공간(?) 복잡도를 공부해야 확실히 알 수 있다고 하셨다(O(N) 이런 것) 전에 조금 공부해보다가 너무 복잡해져 어렵다고 느껴 그만 두었는데 역시 이 방법이 정도인듯하여 공부를 다시금 해줘야 할 것 같다
강의부분에서 내가 실수로 reset_index를 빼먹었을 때 merge를 통해 join했을 경우 컬럼명이 tip_x, tip_y 이런식으로 따로 컬럼명을 정해줬음에도 불구하고 나오는 이유에 대해 여쭤봤는데
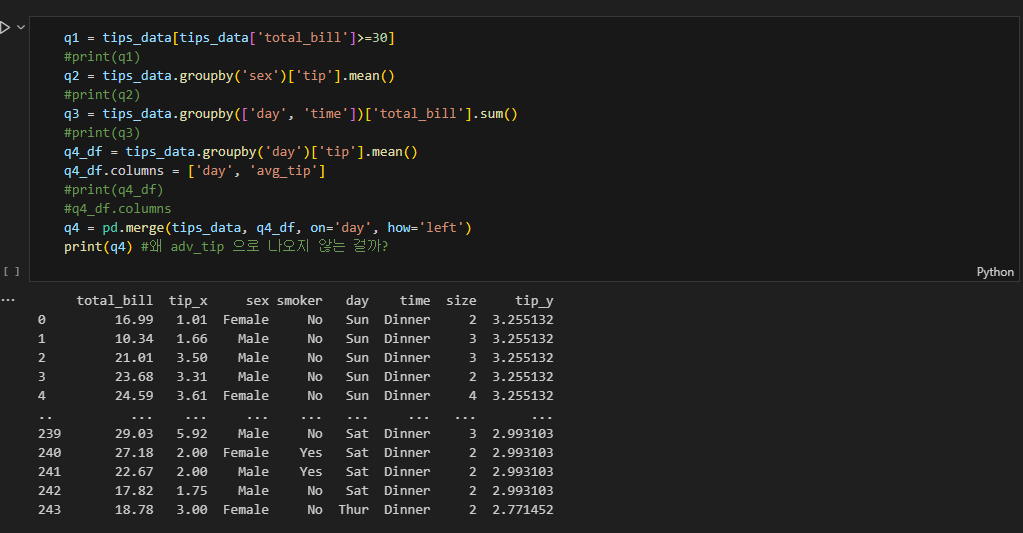
index가 문자열로 부여되어있어서 (형태가 달라서) 그런듯 tips는 숫자로 0123라서 맞춰줘야했음
groupby 하면 df가 아니라 df.groupby 객체 형태로 다른 형태로 바뀌는데 reset_index하면 다시 인덱스 부여해주면서 df로 형태 바꿔줌 이라는 결론을 직접 몇몇 부분을 print 등을 통해 확인해보며 알 수 있게 되었다
그리고 추가 여담으로 \n은 줄바꿈 해주는 것이라고는 알고있는데 이러한 것을 뭐라고 하는지 궁금해 여쭤보니 용어를 튜터님도 잘안쓰셔서 기억이 안나 같이 찾아주신 결과 이스케이프 시퀀스라고 하는 듯하였다. 그리고 파이썬은 인덴트(들여쓰기)와 \n정도만 많이 써서 아마 둘만 알아도 충분할 것이라고 말씀하셨다
그리고 vscode의 경우 코드가 셀로 나눠져 있어 위의 셀에서 실행했을 경우 그 결과가 남아 아래에서는 추가적으로 패키지 등을 import할 필요가 없지만 컴퓨터를 껐다 켰을 경우라던지 그럴 경우에는 위의 실행 결과가 날아가 있는 상태라 그냥 아래 부분을 실행하면 error 나는데 이럴 경우 일일히 위로 가서 필요한 부분을 실행하지 않기 위해 import를 아래에도 적는 식의 여러번 적어도 성능 등에 크게 영향이 없을지 여쭤봤는데 아마 크게 영향 없어 신경쓰지 않아도 될듯 하지만 굳이 이렇게 예방위해 여러번 적어주지말고 연결되는 코드는 마지막에 한번에 합쳐 정리하는 식의 방식을 해보면 좋을 것 같다고 말씀해주셨다
그리고 추가로 matplotlib에서 box plot을 그릴려면 데이터는 x축갑에 대해 리스트 등의 덩어리의 형태로 넣어줘야한다고 하셨다 그래서 저런 for등의 반복문 형태로 리스트를 넣어 주신 것이라고 하셨다
matplotlib에서 boxplot을 썼을 때와 seaborn에서 썼을 때 차이와 장단점을 알 수 있을까 여쭤보았지만 조금 애매한 느낌의 답변이 돌아와서 명쾌히 결론을 얻지 못하였다 아마 이부분은 직접 써보면서 느껴야할듯하다
(추가 여담으로 내가 질문 드린 튜터님은 파이썬이 주로 쓰시던 언어가 아니시라 좀 미숙하신 편이라고 하셨다! (살짝 충격적이였다 ㅎㅎ 전에 질문드렸을 때 이런 중요한 부분을 본인이 맡게된 이유를 모르겠다면서 자신감없는 모습을 보여주신 이유가 있었던 것 같다, 추가로 강의도 감기에 걸리셔서 10초에 한번씩은 기침이 나오는 상황이라 화면녹화하고 음성은 10초씩 녹음하고 끊고 하여 편집으로 붙이는 방식의 엄청난 고생을 하셨다고 하셨다..ㅠㅠ))
그리고 그래프 사이즈 변경 부분 xlabel과 set_xlabel차이에 관련해서 여쭤봤는데
set_xlabel 메소드 (특정 객체에 지정된 것을 변경할 때 활용) 이미 x축같은 게 활성화되어있는 그래프의 경우 바꾸고 싶을 때 xlabel 사용가능이라고 설명해주셨다 한 80~90프로 정도 이해가 갔었는데 마침 내가 질문하고 나서 조금 있다가 슬랙 질문방에도 유사한 질문이 올라와서 다른 분들도 답변 달아주신 부분을 읽고나니 어느정도 이해가 더 된 듯했다(pyplot방식과 객체지향방식의 차이라는 듯하다)
그리고 sns.boxplot에서 palette? 관련해서 옵션 어떤게 있는지? 그리고 추가로 hue가 어떤 것을 의미하는지? 여쭤봤는데 palette는 다른 그래프에서 color=이렇게 설정하던 색깔 정해주는 느낌의 설정 옵션이라고 생각하면 될듯하고, hue는 이런식으로 각자 색을 다르게 줄때 어느 것을 기준으로 색을 다르게 줄것이냐를 적는 인자라고 한다
그리고 마지막으로 10분 판다스를 매일 익숙해지기 위해 직접 타이핑 해보는 용도로 활용하라고 하셨는데 그게 어떤 방식으로 활용을 의미하는 것인지 더 자세히 알려달라고 부탁드리니 직접 목차나 이런 부분에서 하나 들어가서 거기에 있는 예제와 in에 적혀있는 코드를 직접 손으로 따라치고 실행하는 방식으로 사용하면 좋을 것이라 생각한다고 하셨다 현재 pandas 어느정도 사용법은 알지만 아직 익숙하지 않아서 뜨문뜨문 느리게 사용하는 데 조언해주신 대로 이제 내일부터 큰일이 없는 이상 코드카타하는 느낌으로 매일 10분씩이라도 꾸준히 사용한다면 익숙해질 듯하다(그리고 초반에는 특정 여유가 되는 날을 잡아서 좀 오래 잡고 사용해봐야 확실히 친숙해 질 듯하다.)
오늘은 SQL은 간단히 하였고, 국민취업지원제도 관련 상담을 다녀와서 덜한 과제부분을 마저 마무리하고 그외 조금 통계강의 복습하고, 질문하고 싶었던 부분들을 정리해서 질문을 많이 드렸다(총 좀관련 있다고 생각하는 튜터분들께 가서 3분께 나눠서 질문을 드렸다) 정리하다 보니 많은 양을 질문드려서 다 기억할 수 있을지 모르겠지만 기록해뒀으니 다시 보면 떠오를 것이라고 생각한다.
그리고 앞으로 자료구조에 대해서도 더 자세히 공부할려고 노력하고, 시간복잡도에 관해서도 다시 조금씩 공부해가며, 판다스 익숙해지는 과정도 시작해야할 듯하다(앞으로 공부할 내용이 너무 많다 더 열심히 게을러 지지말고 노력해야할 듯하다)
'스파르타 > TIL(Today I Learned)' 카테고리의 다른 글
2024-01-27~2024-01-28 (2) 2024.01.29 2024-01-26 (1) 2024.01.26 2024-01-24 (1) 2024.01.24 2024-01-23 (2) 2024.01.23 2024-01-22 (2) 2024.01.22