-
2024-01-09스파르타/TIL(Today I Learned) 2024. 1. 9. 23:42더보기
SQL 코드카타
그룹별 조건에 맞는 식당 목록 출력하기(SQL) (with, max, date_format, where절 서브쿼리 조건)
https://school.programmers.co.kr/learn/courses/30/lessons/131124
`MEMBER_PROFILE`와 `REST_REVIEW` 테이블에서 리뷰를 가장 많이 작성한 회원의 리뷰들을 조회하는 SQL문을 작성해주세요. 회원 이름, 리뷰 텍스트, 리뷰 작성일이 출력되도록 작성해주시고, 결과는 리뷰 작성일을 기준으로 오름차순, 리뷰 작성일이 같다면 리뷰 텍스트를 기준으로 오름차순 정렬해주세요. 라는 문제이다.
우선 가장 리뷰를 많이 쓴 회원을 필터링 해주는 조건부터 만들어봐야할 듯하여 시도하였는데 생각 만큼 스무스하게 되지 않았다 우선 방법은 시도해서 성공한 것들 중 위의 리뷰를 count한 컬럼이 포함된 테이블을 가져와서 max를 따로 구하는 방식을 선택하여 사용하였다.#최대값 구하는 것 max로 구하는 방식 처음 시도해봤던 것 SELECT max(a.cnt_review) FROM ( SELECT rev_sub.MEMBER_ID, count(rev_sub.REVIEW_ID) cnt_review FROM REST_REVIEW rev_sub GROUP BY rev_sub.MEMBER_ID )a #다른 방식 한 것 SELECT count(rev_sub.REVIEW_ID) cnt FROM REST_REVIEW rev_sub GROUP BY rev_sub.MEMBER_ID ORDER BY cnt desc LIMIT 1아래 쿼리가 최종적으로 제출한 쿼리이다
WITH REVIW_MERGE as( SELECT pro.MEMBER_NAME, rev.MEMBER_ID, rev.REVIEW_TEXT, date_format(rev.REVIEW_DATE,'%Y-%m-%d') REVIEW_DATE FROM REST_REVIEW rev JOIN MEMBER_PROFILE pro on rev.MEMBER_ID=pro.MEMBER_ID ), Count_review as( SELECT rev_sub.MEMBER_ID, count(rev_sub.REVIEW_ID) cnt_review FROM REST_REVIEW rev_sub GROUP BY rev_sub.MEMBER_ID ) SELECT rm.MEMBER_NAME, rm.REVIEW_TEXT, rm.REVIEW_DATE FROM REVIW_MERGE rm JOIN Count_review cnt on rm.MEMBER_ID = cnt.MEMBER_ID WHERE cnt.cnt_review = (SELECT MAX(cnt_review) FROM Count_review) ORDER BY rm.REVIEW_DATE, rm.REVIEW_TEXT우선 작성하다 조금 헷깔리는 부분이 많아서 다른 분이 with구문을 사용한 것을 보고 참고하여 틀을 살짝 바꿔서 작성해주었다 확실히 with구문을 사용하니 덜 복잡하고 가독성이 더 좋아진 것 같았다.
쿼리에 대하여 간단히 설명하면 우선 with 구문을 사용하여 REST_REVIEW테이블과 MEMBER_PROFILE테이블을 MEMBER_ID를 공통컬럼으로 사용하여 join해주었고 MEMBER_NAME, MEMBER_ID, REVIEW_TEXT와 date_format(rev.REVIEW_DATE,'%Y-%m-%d')으로 형식을 바꿔준 리뷰날짜를 컬럼으로 하는 테이블 REVIW_MERGE를 선언해주었다.
그리고 REST_REVIEW테이블로 부터 MEMBER_ID로 그룹을 지어 MEMBER_ID와 각 작성된 리뷰의 갯수를 세어준 컬럼을 갖는 테이블 Count_review도 선언해주었다
그 뒤 마지막으로 두 테이블을 MEMBER_ID를 공통 컬럼으로 하여 join해 주고 where절에서 서브쿼리로 count_review로부터 회원별 리뷰갯수의 최대갯수를 구하는 쿼리를 작성하여 회원별 리뷰갯수가 동일한 데이터에 대해서만 출력되도록 필터링 해주었다. 그 뒤 회원이름, 리뷰내용, 날짜를 출력되게 하는데 날짜, 리뷰내용을 순서로 오름차순 정렬하였다
그런데 이 문제가 조금 이상했던 것이 문제에서는 가장 많은 한명인 듯 말하는 것처럼 해석될 수도 있는 느낌이였는데 실제 데이터를 살펴보면 리뷰를 가장 많이 쓴사람의 쓴 갯수는 3개이다. 하지만 3개를 쓴 사람은 3명이라서 오류가 생긴 것인지 어떤 사람은 그 3명 중 한명의 리뷰 3개를 다보여주기만 해도 통과 되었다는 것을 확인했다. 이부분에 대해선 개선되었으면 좋겠지만 SQL쪽은 따로 개선요청 등이 안보여서 이런 문제점이 있다는 것만 파악하고 넘어가야 할듯하다.
여담으로 스프레드시트 쪽에서 구글폼으로 풀었다고 제출할 때 인지한 사실인데 제목도 먼가 맞지 않는 듯하다. 그룹별 조건에 맞는 식당 목록 출력인데 한 내용은 리뷰 가장 많이 쓴 회원의 리뷰 출력이였으니 말이다.
오프라인/온라인 판매 데이터 통합하기(SQL) (union set operation, date_format, wtih, 날짜 필터조건)
https://school.programmers.co.kr/learn/courses/30/lessons/131537
`ONLINE_SALE` 테이블과 `OFFLINE_SALE` 테이블에서 2022년 3월의 오프라인/온라인 상품 판매 데이터의 판매 날짜, 상품ID, 유저ID, 판매량을 출력하는 SQL문을 작성해주세요. `OFFLINE_SALE` 테이블의 판매 데이터의 `USER_ID` 값은 NULL 로 표시해주세요. 결과는 판매일을 기준으로 오름차순 정렬해주시고 판매일이 같다면 상품 ID를 기준으로 오름차순, 상품ID까지 같다면 유저 ID를 기준으로 오름차순 정렬해주세요. 라는 문제이다.
처음에는 테이블 두개고 두 테이블의 데이터 가져다 써야하네 join의 사고과정을 거쳤지만 쿼리를 작성하면서 먼가 이상함을 느끼고 다시 생각하니 join 은 옆으로 컬럼을 붙이는 것이고 지금 문제가 요구하는 것은 아래로 행을 데이터로써 더 붙이라는 의미이다. 따라서 SET OPERATION을 사용하여야 할 것 같아서 보니 둘을 합쳐야 하니 union을 써야하는데 union을 써야할지 union all을 써야할지는 조금 고민 되었다. 하지만 굳이 중복해서 더 적을 필요도 없을듯했고 애초에 두 데이터 사이에 중복이 없을 것이라 굳이 고민할 필요가 없을 듯하여 그냥 union을 사용하였다(후술할 이번에도 문제에서 얘기한 날짜범위가 이상하다) 데이터를 직접 살펴보면 online은 판매 데이터가 22년 1월부터 3월 초까지의 데이터가 있지만 offline의 데이터의 경우 팔린 것이 없어서 그럴 가능성도 있지만 어찌됬든 22년 1월부터 2월초까지 데이터 밖에 없다 그래서 3월 데이터는 하나도 없는데 문제에서 요구하는 데이터는 3월달 데이터라는 아이러니다.. 그래서 똑바로 기능하는지 확인 할때는 1월 데이터 기준으로 확인해보고 마지막에 3월로 바꿔서 제출하였다.WITH MERGE_SALE as( SELECT date_format(onl.SALES_DATE,'%Y-%m-%d') SALES_DATE, onl.PRODUCT_ID, onl.USER_ID, onl.SALES_AMOUNT FROM ONLINE_SALE onl UNION SELECT date_format(offl.SALES_DATE,'%Y-%m-%d') SALES_DATE, offl.PRODUCT_ID, NULL USER_ID, offl.SALES_AMOUNT FROM OFFLINE_SALE offl) SELECT ms.SALES_DATE,ms.PRODUCT_ID,ms.USER_ID,ms.SALES_AMOUNT FROM MERGE_SALE ms WHERE year(ms.SALES_DATE)='2022' and month(ms.SALES_DATE)='03' ORDER BY ms.SALES_DATE, ms.PRODUCT_ID,ms.USER_ID쿼리에 대해서 설명하자면 우선 각각 온라인과 오프라인 테이블에 대하여 판매날짜, 상품id, 유저id, 판매량을 출력하는 쿼리를 작성해준 뒤 union을 통해 합쳐주었다(이때 오프라인 데이터는 user_id에 대한 데이터가 없기에 null로 값을 채워주었다) 그뒤 with구문을 통해 MERGE_SALE이라는 테이블로 선언해주었고 그 테이블을 가져와서 날짜가 2022년 3월인 데이터에 대해서만 필터링하여 날짜, 상품id, 유저id, 판매량을 출력하도록 하는데 날짜,상품id, user_id에 대해 오름차순 정렬해주었다.
그리고 이번에 union을 써본 것이 처음이라 이것 저것 되나 싶은 것들을 몇 개 실험해보았다
내용은 주석으로 아래 적어 두었다.
SELECT date_format(onl.SALES_DATE,'%Y-%m-%d') SALES_DATE, onl.PRODUCT_ID, onl.USER_ID, onl.SALES_AMOUNT FROM ONLINE_SALE onl UNION SELECT date_format(offl.SALES_DATE,'%Y-%m-%d') SALES_DATE, offl.PRODUCT_ID, offl.SALES_AMOUNT FROM OFFLINE_SALE offl #SQL 실행 중 오류가 발생하였습니다. #The used SELECT statements have a different number of columns #둘의 컬럼 수가 다르면 union못하는 듯 SELECT date_format(onl.SALES_DATE,'%Y-%m-%d') SALES_DATE, onl.PRODUCT_ID, onl.USER_ID, onl.SALES_AMOUNT FROM ONLINE_SALE onl UNION SELECT date_format(offl.SALES_DATE,'%Y-%m-%d') SALES_DATE, offl.PRODUCT_ID, offl.SALES_AMOUNT , NULL USER_ID FROM OFFLINE_SALE offl #순서도 맞춰서 써야하는 듯 순서 다르게 해서 하니까 그냥 값만 붙이는 느낌그리고 아마 안되지 않을까 싶은데 where 나중에 최종적으로 한번에 줄 방법은 이걸 또 서브쿼리쓰던지 해서 하는 방법 말고는 없을 듯하다
조건에 부합하는 중고거래 댓글 조회하기(SQL) (date_format, month,날짜 필터조건) (아래 month in 쓰는 방식 적어둠)
https://school.programmers.co.kr/learn/courses/30/lessons/164673
USED_GOODS_BOARD와 USED_GOODS_REPLY 테이블에서 2022년 10월에 작성된 게시글 제목, 게시글 ID, 댓글 ID, 댓글 작성자 ID, 댓글 내용, 댓글 작성일을 조회하는 SQL문을 작성해주세요. 결과는 댓글 작성일을 기준으로 오름차순 정렬해주시고, 댓글 작성일이 같다면 게시글 제목을 기준으로 오름차순 정렬해주세요. 라는 문제이다.
SELECT brd.TITLE, rly.BOARD_ID, rly.REPLY_ID, rly.WRITER_ID, rly.CONTENTS, date_format(rly.CREATED_DATE,'%Y-%m-%d') FROM USED_GOODS_REPLY rly JOIN USED_GOODS_BOARD brd on rly.BOARD_ID = brd.BOARD_ID WHERE MONTH(brd.CREATED_DATE) = '10' ORDER BY rly.CREATED_DATE, brd.TITLE이번 문제는 작성된 기준 날짜 범위가 게시물 기준인지, 댓글 기준인지 정확하지 않아 조금 고민되었다(나는 게시물이라고 생각하고 작성하였다, 사실 확인해본 결과로는 주어진 범위인 22년 10월에는 둘 중 뭘로 하든 똑같은 데이터가 선택되기 때문에 상관이 없기는 했다. 애매한 경우 11월말에 게시글 작성되었는데 댓글은 12월초에 작성 되었을 경우 같은게 문제가 생기는 케이스라고 할 수 있다.)
째든 쿼리에 대해 간략히 설명하자면 먼저 USED_GOODS_REPLY (이하 rly)테이블과 USED_GOODS_BOARD (이하 brd) 테이블을 BOARD_ID를 공통 컬럼으로 join해서 데이터를 가져오는데 달이 10월인 데이터로 필터링해서 가져왔다 그리고 게시글 제목, 게시글 id, 댓글id, 댓글작성자id, 댓글 내용, 댓글 작성일(date_format을 이용해서 매번하던 형태로 변환)해서 출력하는데 댓글작성일과 게시글 제목을 기준으로 오름차순 정렬해주었다.
입양 시각 구하기(2)(SQL) (hour, RECURSIVE 재귀, with, case when, left join, set @ : , 반복문 for while 프로시저 생성, 자동으로 정렬되어있는 것의 기준?)
https://school.programmers.co.kr/learn/courses/30/lessons/59413
보호소에서는 몇 시에 입양이 가장 활발하게 일어나는지 알아보려 합니다. 0시부터 23시까지, 각 시간대별로 입양이 몇 건이나 발생했는지 조회하는 SQL문을 작성해주세요. 이때 결과는 시간대 순으로 정렬해야 합니다. 라는 문제이다.
우선 처음에는 별 생각없이 있는 시간대 데이터에 대해서만 표기 하면 되겠지라고 생각하여 그냥 ANIMBAL_OUTS테이블에서 가져와서 DATETIME에 대해 시에 그룹을 지은 다음 그리고 그것과 그룹 별 ANIMAL_ID의 수를 출력하도록하였다(HOUR에 따라 오름차순 정렬하였다)
SELECT hour(outs.DATETIME) HOUR, count(outs.ANIMAL_ID) COUNT FROM ANIMAL_OUTS outs GROUP BY HOUR ORDER BY HOUR하지만 문제의 의도는 0시~23시까지 전부 표기하는 것 이였고 없는 값에 대해 0부터 23까지 전부 표시 되도록 행 값을 추가해줘야했다.
그래서 검색을 통해 찾아본 방법으로 mysql 8.0버전 이상에서는 다음과 같이 사용하면 만들어 낼수 있다고 한다 아래 쿼리는 1부터 10까지 행 만드는 것(아래 사진과 같이 나오며 아래로 10까지 숫자가 나온다) 좀 더 원리에 대해 설명해보자면 RECURSIVE는 재귀함수 같은 것으로 재귀시키는 듯하다 n이 1부터 n+1까지 n<10까지 반복되는 듯하여 반복하여 행을 만드는 듯하다(대강 재귀라는 사실을 들은 것과, 대략적인 쿼리의 형태를 보고 추정하였다) 특이한 것이 오늘 알고리즘 특강을 하면서 주로 파이썬 관련해서 얘기가 되는데 재귀부분 설명하다가 오늘 질문이 들어왔던 것 중에서 SQL에서도 재귀가 있다면서 관련 내용이 있다고 들었는데 그러고 오후에 SQL코드카타문제를 풀다가 똑같이 그 상황에 만나게 되었는데 기막힌 우연이라 신기하다.
WITH RECURSIVE cte AS ( SELECT 1 AS n UNION ALL SELECT n + 1 FROM cte WHERE n < 10 ) SELECT n FROM cte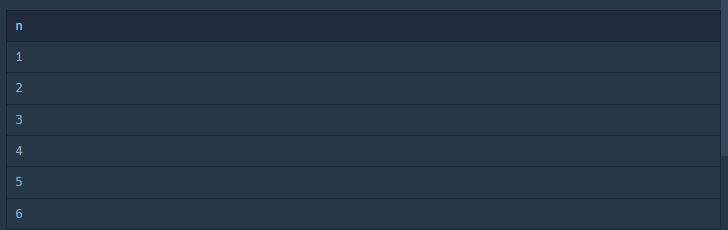

WITH RECURSIVE h_list AS ( SELECT 0 AS hour_num UNION ALL SELECT hour_num + 1 FROM h_list WHERE hour_num < 23 ), hour_outs AS ( SELECT hour(outs.DATETIME) HOUR, count(outs.ANIMAL_ID) COUNT FROM ANIMAL_OUTS outs GROUP BY hour(outs.DATETIME) ) SELECT h.hour_num HOUR, case when ho.COUNT is not null Then ho.COUNT when ho.COUNT is null THEN 0 end COUNT FROM h_list h LEFT JOIN hour_outs ho on h.hour_num = ho.HOUR ORDER BY h.hour_num그래서 쿼리에 대해 간단히 설명하면
우선 with구문을 통해 0~23까지 행을 가지게 하는 h_list테이블을 선언해주고, 위에서 작성했던 쿼리를 정렬하는 부분만 제외하고 hour_outs이라는 테이블로 선언해주었다
그리고 h_list와 hour_outs를 각 h.hour_num와 ho.HOUR을 공통 컬럼으로 left join해주었다(애초에 시간대가 7~19시 밖에 없어서 나머지 빈 부분을 채워 0~23를 전부 표시해 주기위해 h_list를 만든 것이므로, inner join하면 공통되는 7~19만 표시된다) 그리고 h.hour_num을 HOUR로 시간대별 입양된 동물 수 를 COUNT로 하는데 COUNT는 값이 비어있다면 0으로 표기하게 하고 값이 있다면 값이 표시되게 case when을 사용하였다. 그런 뒤 시간대로 오름차순 정렬해주었다(사실 정렬하는 부분은 생략해줘도 결과가 동일하게 출력된다 아마 h_list은 원래 0부터 23까지 순서대로 되어있는데 h_list에 join해주었기 때문에 거기에 맞춰서 데이터가 나열됐기 때문일 듯하다-추가 테스트 해본 결과 조인해준 순서나 on 뒤에 순서는 상관 없는 듯하다 모두 결과가 동일하였다 컬럼의 순서도 아닌 것 같고 이유를 모르겠다… 질문을 통해 확인해보는 것이 좋을 듯하다)
그리고 추가로 다른 분들은 어떻게 볼려다가 새로 보는 것을 발견해 어떤 것인지 궁금해서 찾아보았다(정확히는 키워드를 뭐라 검색해야 할지 모르겠어서 chatGPT에게 설명해달라고 하고 세부적으로 @가 의미가 뭔지, select에서 : 부분이 뭘 의미하는지 물어보았다)
@는 우선 사용지정의변수라고 한다 사용자 정의 변수는 쿼리나 프로시저에서 값을 저장하고 재사용하는 데 사용됩니다. 이 변수는 @ 기호 뒤에 오는 이름으로 정의할 때 쓰인다고 하는데 아마 set을 쓸 때 사용되는 것 같다. 그리고 :는 대입 연산자라고 한다 제일 처음 @Hour : =-1는 @Hour의 초기값을 -1로 정의 한다는 의미인 듯하다. 그리고 select구문?의 제일 처음 (@HOUR := @HOUR + 1) AS HOUR은 파이썬의 n=n+1과 동일한 의미를 가지는 듯하다 n에+1해주겠다는 의미이다 그 외는 크게 다른 부분은 없어 보였으나 컬럼으로 서브쿼리 쓰는 부분에서 연결하는 부분이 살짝 낯설었고, 마지막 where에 몇까지 반복하는지 정해주는 것을 적어 주는 듯하였다
SET @HOUR := -1; SELECT (@HOUR := @HOUR + 1) AS HOUR, (SELECT COUNT(*) FROM ANIMAL_OUTS WHERE HOUR(DATETIME) = @HOUR) AS COUNT FROM ANIMAL_OUTS WHERE @HOUR < 23 #권재혁추가로 SQL에서도 파이썬의 for문처럼 작동하는 것을 만들 수 있는데 while을 이용한 프로시저를 생성하여 만든다고 한다. 사용해보진 않아서 검색하다 있길래 아 이런 것이 있구나 하고 일단은 넘어갔다
더보기파이썬 프로그래머스 문제 (알고리즘 관련된?)
완주하지 못한 선수(python) (개인과제, f-string, zip, collections 의 counter, 해시,알고리즘)
https://school.programmers.co.kr/learn/courses/30/lessons/42576
참여자 명단과 완주자 명단을 주고 완주하지 못한 1명의 이름을 답하는 문제이다.
파이썬 개인과제로도 동일한 문제가 나왔었는데 그때는 따로 성능에 대한 제한이 없이 그냥 기능만 하면 되서 간단히 적어서 냈는데 해시 문제중 쉬운 것을 찾다 보니 프로그래머스에도 있다는 것을 확인하게 되었다. 우선 아래에 과제에 제출한 코드인데 간단하게 for문 하나에서 in을 통해 리스트 안에 있는지 일일히 비교하는 방식으로 하였는데 효율성 체크 부분에서 실패하였다.
아래 코드가 과제로 제출한 코드이다
def find_non_completer(participant,completion): fail_name='' #한명이라 확정하는 전제가 있기에 문자열 for name in participant: if name in completion: completion.remove(name) #remove는 해당하는 첫번째 것만 제거하므로 else: fail_name=name return '1명의 미완주자는 '+fail_name아래는 프로그래머스에 제출한 코드이다
def solution(participant, completion): participant.sort() completion.sort() for p,c in zip(participant,completion): if p!=c: #다르면 그 사람이 완주 못한 것 return p return participant[-1] #테스트 해본 결과 for~ zip은 짧은 것 기준으로 짧은 것이 끝날 때 까지 돌아간다그래서 정렬하고 비교해서 다르면 출력하는 방식으로 하여 제출하였는데 해시방식을 쓴 느낌도 아니고 다른 사람은 어떻게 했나 싶어서 찾아보니 가장 위에 올라와 있는 풀이를 보면 collections라는 모듈에서 counter라는 메소드를 사용한 방식인데 counter가 내가 매번 일일히 몇 개 있는지 세어서 딕셔너리 만들었던 그 작업을 대신 해주는 메소드 인듯 하였다. 딕셔너리는 값끼리 빼지 못하지만 count의 객체는 뺄 수 있어 빼서 중복되는 것을 한번에 제거하고 남은 것의 키값을 리턴하는 방식이였다.
import collections def solution(participant, completion): answer = collections.Counter(participant) - collections.Counter(completion) return list(answer.keys())[0]여담으로 다른 모듈에서도 counter라는 메소드를 본적이 있는 듯한데 자주쓰이는 이름인듯하다 여러개 import해서 사용할 때 주의해야 할듯하다
전화번호 목록 (python) (해시, 알고리즘, 리스트 인덱스 뒷부분 슬라이싱, startswith 시작위치 문자열 찾기)
https://school.programmers.co.kr/learn/courses/30/lessons/42577
해시 문제인데 대강 설명하자면 여러 번호가 주어지는데 어떤 번호가 어떤 번호의 접두사가 되지 않는지 확인 하는 문제이다.
처음에 해시라 그러고 해시이니 딕셔너리를 활용해 키:밸류 를 활용해서 풀어야 의도에 맞다 생각해 열심히 해봤지만 한 문제에서 시간초과를 줄이지 못하여 결국 다른 분들의 풀이나 힌트를 참고하였는데 딕셔너리를 쓰지 않고들 풀었다는 것을 확인했다… 그런데 이해가 안되는게 이게 왜 해시 문제라고 하는지 모르겠다 해시를 사용해서 푼 분이 있어 제일 아래 부분에 코드를 복붙해놓았다 해시를 이용해 풀 수 있는 것을 확인했지만 솔직히 그리 효율적인가?하는 부분에서는 잘 모르겠다… 그리고 저렇게 비교한게 내가 처음 짠 것보다 빠른 이유를 아직 이해하지 못하여서 좀 더 생각해봐야겠다
def solution(phone_book): phone_book.sort() for i in range(len(phone_book)-1): if phone_book[i]==phone_book[i+1][:len(phone_book[i])]: return False return True위 코드로 최종 제출하였는데 먼저 정렬을 해준 뒤, 코드를 간단히 설명하면 마지막 것을 제외한 나머지 전화번호들에 대해 반복하는데
인접한 번호들에 대해서만 앞의 번호의 글자수 만큼 확인해준다. 같으면 접두어가 되는 것이니 False 아니면 True를 리턴한다
그리고 추가로 인덱스 자를 때 앞 번호가 뒷번호 보다 길면 에러나지 않나라는 생각을 가지고 있었는데 확인해본결과 뒤에 슬라이싱 하는 것은 실제 길이보다 큰 값으로 자르게 표시해도 문제없이 작동하였다
a='abcdef' print(a[:20]) b=[1,2,3,4,5,6,78,9] print(b[:20]) #처음 안 사실 인덱스 슬라이싱으로 자를 때 #뒷부분 표시는 문자열이나 리스트의 길이보다 더 큰값으로 해도 에러없이 잘 작동한다.그리고 다른 방식으로 한 사람들을 쭉 훑어 보고 있는데 새로운 유용한 메소드를 발견하여 기록해둔다.
특정 문자 찾기 관련 메소드로 문자열.find(찾을문자, 찾기시작할 위치)로 찾고 위치를 반환해주는데 없을 경우 -1을 리턴해주며, 찾기시작할 위치 부터 검색을 한다고 생각하면 된다(그러니 검색 시작 위치보다 뒤에는 없고 앞에만 존재한다면 존재하더라도 -1이 반환되게 됨)
문자열.startswith(시작하는 문자, 시작지점) 문자열이 특정문자로 시작하는지 여부를 알려주며 True와 False로 반환된다 두번째 인자를 넣음으로써 찾기시작할 지점을 정할 수 있다.유사하게 끝나는 문자 확인 하는 메소드로endswith도 있다.
그래서 굳이 슬라이싱 할 필요없이 startwith라는 메소드를 사용해도 될 듯 하다
해시의 정석대로 푼듯한 분도 있었는데 내가 잘 몰라서 그런지 사실 굳이 저렇게 까지 해시로 풀면 이득이 있나라는 생각이 들었다
우선 코드는 아래와 같다
def solution(phone_book): answer = True hash_map = {} for phone_number in phone_book: hash_map[phone_number] = 1 for phone_number in phone_book: temp = "" for number in phone_number: temp += number if temp in hash_map and temp != phone_number: answer = False return answer(설명은 딕셔너리를 사용했다는 점 제외하고는 위의 방식과 크게 다르지 않아서 생략하겠다)
def solution(phone_book): answer = True len_num={} for phone_num in phone_book: #딕셔너리 형태로 저장 len_num[phone_num] = len(phone_num) type_len=sorted(list(set(len_num.values()))) #두 번 째로 길이가 긴 것만큼 돌아갔으면 종료(중복없으므로) #길이 젤 긴 것은 확인 할 필요 X for l in type_len[:-1]: #길이가 l인 글자들에 대해서만 확인 for check in [i for i in len_num if len_num[i]==l]: #글자 길이가 더 길고 접두어인지 확인할 글자(check)와 #첫글자가 같은 글자에 대하여 속하는지 확인 for ob in [i for i in len_num if (len_num[i]>l and check[0]==i[0])]: if check == ob[:l]: return False return answer위 코드는 내가 처음으로 떠올려 작성했던 방법이다 처음에 해시 알고리즘 문제라길래 해시 알고리즘 어떤 것인가 하니 대강 키와 값으로 주어진 자료형을 사용하여 해시함수를 이용해 주소를 배정해주는 아직 완벽히 이해한 것은 아니고 대강만 이해를 해서 빠르게 적자면 이정도 밖에 못 적을 듯한데, 째든 딕셔너리로 글자수를 값으로 가지게 각 문자열에 대하여 저장해주고 길이 종류를 정렬해서 리스트로 만들어준뒤 글자 수대로 제일 짧은 것부터 나머지 번호의 글자수가 더 길고, 확인하는 짧은 것과 첫글자가 같은 것에 대해서만 짧은 것의 글자수대로 비교하여 False True를 리턴해주는 방식으로 했는데 정확성은 다 통과하였으나 효율성 측정에서 마지막 테스트4번을 시간초과나여 실패하고 말았다
그래서 컴프리헨션으로 했지만 리스트를 반복문통해 매반복마다 두번이나 만들어주는게 시간이 늘어나는데 영향을 끼쳤을 듯하여 아래와 같이 수정하였다
#체크할 리스트를 컴프리헨션 썼지만 매반복마다 두번씩 새로 만드는게 부담일 수있다고 생각 #그래서 따로 미리 만들어줬음 def solution(phone_book): answer = True len_num={} for phone_num in phone_book: len_num[phone_num] = len(phone_num) type_len=sorted(list(set(len_num.values()))) #두 번 째로 길이가 긴 것만큼 돌아갔으면 종료(중복없으므로) #길이 젤 긴 것은 확인 할 필요 X for l in type_len[:-1]: #길이가 l인 글자들에 대해서만 확인 check_list=[] #접두어 후보들 object_list=[] #접두어로 가지는지 확인할 후보들 for judge in len_num: if len_num[judge]==l: check_list.append(judge) elif len_num[judge]>l: object_list.append(judge) for check in check_list: for ob in [i for i in object_list if check[0]==i[0]]: if check == ob[:l]: return False return answer이전 코드보다 원래 오래 걸리던 테스트 케이스들에 대해 더 빨라지긴 했지만 마찬가지로 효율성 테스트4번을 통과하지 못하였다.
그래서 마지막으로 짧은 부분은 체크하고나서 더이상 필요없지 않을까라는 생각에 확인하기용으로 사용할 리스트 만들고나서 바로 딕셔너리 변수에서 삭제해줬는데 정확성에서도 2문제를 더 틀렸고 걸리는 시간이 짧아지긴 했으나 역시나 효율성 테스트4번은 시간초과로 통과하지 못하였다 여기서 시간을 꽤 많이 소모했다고 판단하여 과감히 다음에 확인 해보던지 할 생각으로 여기서 그만두고 힌트들을 탐색하면서 제일 위의 제출한 코드를 작성하였다
#이래도 시간초과가 해결이 안되서 필요없는 값들은 삭제하자 생각 def solution(phone_book): answer = True len_num={} for phone_num in phone_book: len_num[phone_num] = len(phone_num) type_len=sorted(list(set(len_num.values()))) #두 번 째로 길이가 긴 것만큼 돌아갔으면 종료(중복없으므로) #길이 젤 긴 것은 확인 할 필요 X for l in type_len[:-1]: #길이가 l인 글자들에 대해서만 확인 check_list=[] #접두어 후보들 object_list=[] #접두어로 가지는지 확인할 후보들 diet_len_num=len_num for judge in diet_len_num: if diet_len_num[judge]==l: check_list.append(judge) elif diet_len_num[judge]>l: object_list.append(judge) #추가해준 뒤 딕셔너리에서 제외(이제 쓸일 없으니) del len_num[judge] for check in check_list: for ob in [i for i in object_list if check[0]==i[0]]: if check == ob[:l]: return False return answer #이렇게 하니까 diet~랑 len_num이랑 값복사가 아니라 연결되서 len_num지우니까 diet도 같이 변함#위에 에러 떠서 분리하기 위해 아예 키값만으로 리스트로 만들어버림 def solution(phone_book): answer = True len_num={} for phone_num in phone_book: len_num[phone_num] = len(phone_num) type_len=sorted(list(set(len_num.values()))) #두 번 째로 길이가 긴 것만큼 돌아갔으면 종료(중복없으므로) #길이 젤 긴 것은 확인 할 필요 X for l in type_len[:-1]: #길이가 l인 글자들에 대해서만 확인 check_list=[] #접두어 후보들 object_list=[] #접두어로 가지는지 확인할 후보들 diet_len_num=list(len_num.keys()) for judge in diet_len_num: if len(judge)==l: check_list.append(judge) elif len(judge)>l: object_list.append(judge) #추가해준 뒤 딕셔너리에서 제외(이제 쓸일 없으니) del len_num[judge] for check in check_list: for ob in [i for i in object_list if check[0]==i[0]]: if check == ob[:l]: return False return answer #정확도 부분에서 실패한 문제가 2문제 나오고 #시간초과한 문제 동일하게 시간 초과됨(전체적으로 속도는 빨라지긴 했음) #왜 실패한게 나온지는 아직 이해못함더보기알고리즘 특강 내용 정리
- 알고리즘 이란?
- 입사시험에서의 알고리즘
- 개발자의 능력을 평가하기 위한 문제의 해결 방법
- 자료과 논리를 이용한 조건, 반복문 등으로 구현
- Ex) 완전 탐색, 이진 탐색
- 데이터 분석, 통계, 머신러닝에서의 알고리즘
- 모델링과 그 분석과정에서의 방법론
- 데이터 기반의 수학적 계산으로 구현
- Ex) 선형회귀, 딥러닝 알고리즘
- 입사시험에서의 알고리즘
- 문제를 풀기위한 단계적 절차
- 자료구조란?
- 말그대로 자료를 담는 구조
- 자료형의 특징에 맞춰 그릇을 담는 것은 필수적
- 컴퓨터 과학 관점에서 자료 효율적인 접근과 수정을 가 능하게 하는 구조
- 자료구조에서 등장하는 개념(concept)들을 각 프로그 래밍 언어에 맞춰서 새롭게 불리움 Ex 개념: Array -> Python : List
- 모든 알고리즘과 자료구조를 아는 것은 도움은 되지 만 효율적이지 않음
∴ 핵심 자료구조와 알고리즘을 배우고 이를 프로그래밍 코드에서 비추어 적용해보자
- 배열(Array)

- 가장 직관적인 자료형
- 인덱스의 개념이 존재
- Python 에서는 List라는 이름으로 쉽게 구현할 수 있음
- 검색 : O(1), 추가/삭제 : O(N) (시간복잡도 O(1) : 자료크기 상관없이 속도 일정, O(N) : 자료크기에 비례하여 시간 증가)

자료형만 잘 선정해도 자료처리 속도 엄청 빨라짐

https://school.programmers.co.kr/learn/courses/30/lessons/12910
연결리스트(Linked List)

검색 : O(N), 추가/삭제 : O(1)
- 큐(Queue)
- Queue는 줄서기/ 먼저 들어온 값이 먼저 나감
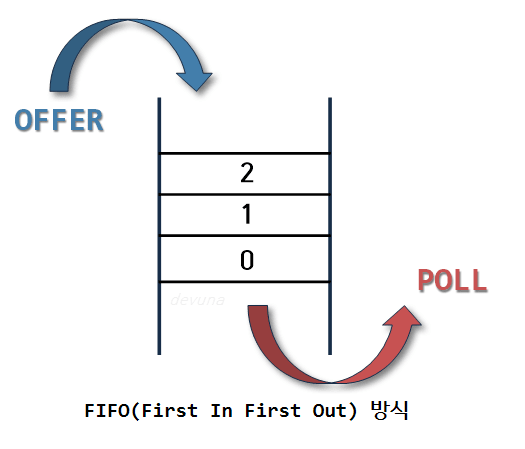

- 스택(Stack)
- 먼저 들어온 값이 나중에 나감
- Stack 은 쌓기
- 값 들어오는 것을 push, 빼는 것을 pop이라 함


스택(Stack) 문제 활용의 대표적인 예: 올바른 괄호 수식
- Hash table

- Key와 Value로 이루어진 “사전형“ 자료형
- Hash Table은 Python 에서 Dictionary 형으로 구현
- 이런 직관적인 형식은 hash function 를 이용해서 가능한 자료구조
- Keys를 주어지면 해당 Value가 저장된 곳을 알려줌(O(1) 시간만에)
- SQL 최적화 방법인 옵티마이저에서도 나옴(모르면 pass!)

- 코드 작성의 우선순위
- (검색) 관련 라이브러리가 있는지 찾아본다.
- (적용) 있다면 어떤 함수 혹은 어떤 자료형의 메소드를 사용해야 하는지 찾아본다. Ex) List의 길이를 for문으로 세는게 아니라 len() 함수를 사용하는 것 처럼
- (생성) 없는데 사용을 자주 할 것 같다 -> 사용자 정의 함수로 만든다.
- (최적화) 대용량 데이터에 자주 사용할 것 같다 -> 성능을 고려한 코드를 작성한다.
(개발자를 부른다)
- Tree
- 다양한 Variation이 있지만 굳이 알 필요는 없음.
- 단, 머신러닝 혹은 분석방법론에서 의사결정나무(Tree) 개념이 등장


- Graph


- 알고리즘
- 그리디 알고리즘(Greedy Algorithm)
- 그리디(Greedy), 탐욕이라는 말에 걸맞게 매순간 가장 좋아보이는 것을 선택하여 문제를 풀어가는 방법
- Ex) 거스름돈 문제
- 그리디 알고리즘(Greedy Algorithm)
- 완전 탐색(Brute Force)
- 완전 탐색이란 알고리즘 문제를 만날 때 가장 먼저 접근해야하는 방 법
- 단순하지만 시간복잡도가 높아질 가능성이 농후함
- 하지만 이만큼 확실한 것 도 없음
- 이분 탐색
- 완전탐색이 전체 모든 경우의 수를 다 찾는 방법이라면, 이분탐색은 Up and Down 게임을 하는 방법임
- 알고리즘에 따라 성능이 향상 되는 것을 보여주는 단적인 사례
- 이분탐색이 유효한 이유는 계속 절반식 나눠서 진행하므로 O(logN)의 시간복잡도를 가지기 때문
- 재귀
- 재귀함수는 코드적인 면에서 효율적이지만 알고리즘을 접하는 입장에서는 꽤나 난해한 방법
- 대표적인 예) 팩토리얼 코딩

출처 : 임정 튜터님 특강 자료
(튜터님 자료에 출처라고 적혀있는 것은
1. 자료구조: https://laboputer.github.io/
2. 이것이 코딩테스트이다,나동빈 저
3. 스택으로 풀수 있는 문제들: https://claude-u.tistory.com/74
4. 한국외대 신찬수 교수님, https://www.youtube.com/@ChanSuShin
5. 파이썬 알고리즘 인터뷰, 박상길 저
6. 나의 알고리즘 공부방법 https://blog.naver.com/bellepoque7/223107480964이렇게 적혀있었다
'스파르타 > TIL(Today I Learned)' 카테고리의 다른 글
2024-01-11 (3) 2024.01.11 2024-01-10 (0) 2024.01.10 2024-01-08 (1) 2024.01.08 2024-01-06~2024-01-07 (1) 2024.01.08 2024-01-05 (1) 2024.01.05 - 알고리즘 이란?